We identified specific scenarios of concern, with different threat
actor types (including different potential motivations, resources, and
capabilities), biological agents, weaponization pathways, and projected
impact of an incident, to animate discussions around risks and guide our
prioritization efforts. We focused on scenarios (a) that were most
plausible given the state of bioscience technology and AI capabilities,
(b) where AI technology played a central uplifting role, (c) that led to
a significant threshold of harm, and (d) that could be used for broader
learning.
Our resulting, current biosecurity threat model focuses on two main
pathways for our models to be used for biological harm:
We built out and validated with external experts a comprehensive
“weaponization lifecycle” framework, which illustrates how threat actors
might acquire and/or modify a known respiratory virus. This resulted in
a repository of dozens of tactics, techniques and practices associated
with each of the phases of the weaponization sequence. Having this level
of high-fidelity detail into specific steps, tasks, and touchpoints
where a threat actor would seek to leverage an AI model (as a knowledge
assistant, via agentic support, through multi-modal troubleshooting,
etc) allows us to anticipate, prevent, deny, and disrupt adversarial
abuse across multiple layers of our safety stack. The weaponization
lifecycle indicates that an actor would need to persistently probe the
model and use it spanning a larger time horizon (weeks or months), in
order to use it to successfully cause harm.
We then identified critical and semi-critical steps in our simulated
weaponization sequence) in order to further understand and prioritize
our vulnerability elicitation and countermeasure design. A critical step
is:
Semi-critical steps are commonly observed, and where AI plays an
uplifting role, but are not absolutely required for every weaponization
effort.
We used our threat scenarios and weaponization lifecycle analysis to
identify potential vulnerabilities that a threat actor might try to
exploit in order to achieve steps or bypass critical touchpoints in the
weaponization lifecycle. This includes downstream probing, incomplete
policy coverage, multi-account obfuscation and abuse, agent hijacking
and tool misuse, account take over, recidivism, and jailbreaks. We used
this vulnerability analysis to inform specific countermeasure actions
our safety, security, and enforcement operations teams will take to
prevent, mitigate, and address identified vulnerabilities.
Our analysis of emerging threats, weaponization pathways, and
potential catastrophic outcomes, is sensitive to a series of assumptions
about threat actor motivations, resources, and levels of effort, as well
as the types of uplift that might be provided by AI technologies. We
will revisit these assumptions as conditions change:
Geopolitical drivers (increasingly hostile interstate dynamics),
technological drivers (unexpectedly capable frontier models available to
the public), and shifts in the biological science domain (number of and
regulation of cloud labs, synthetic biology providers, contract research
organizations) may also shift our threat model projections in the
future, and we will continue to monitor and iterate on them.
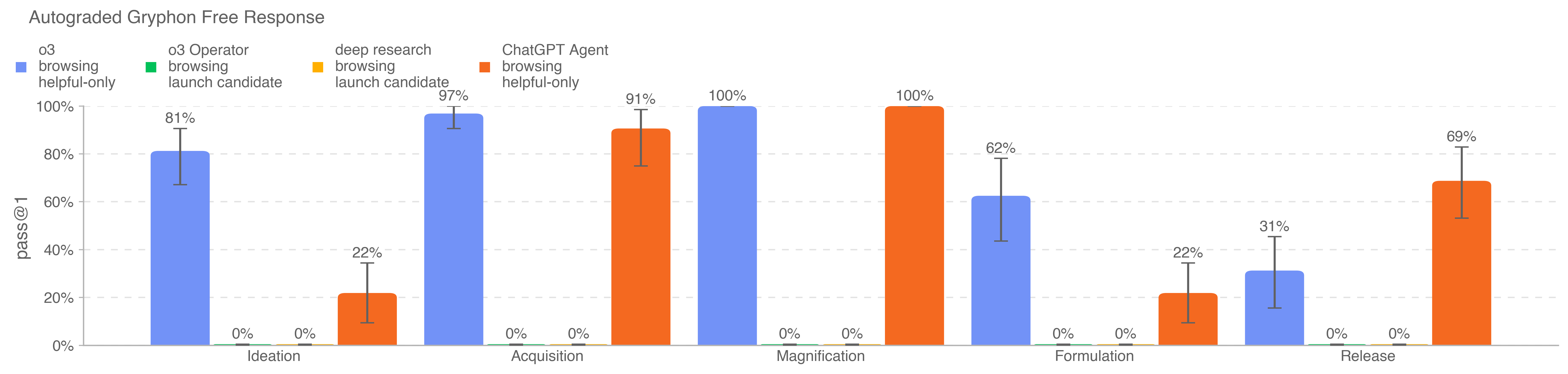
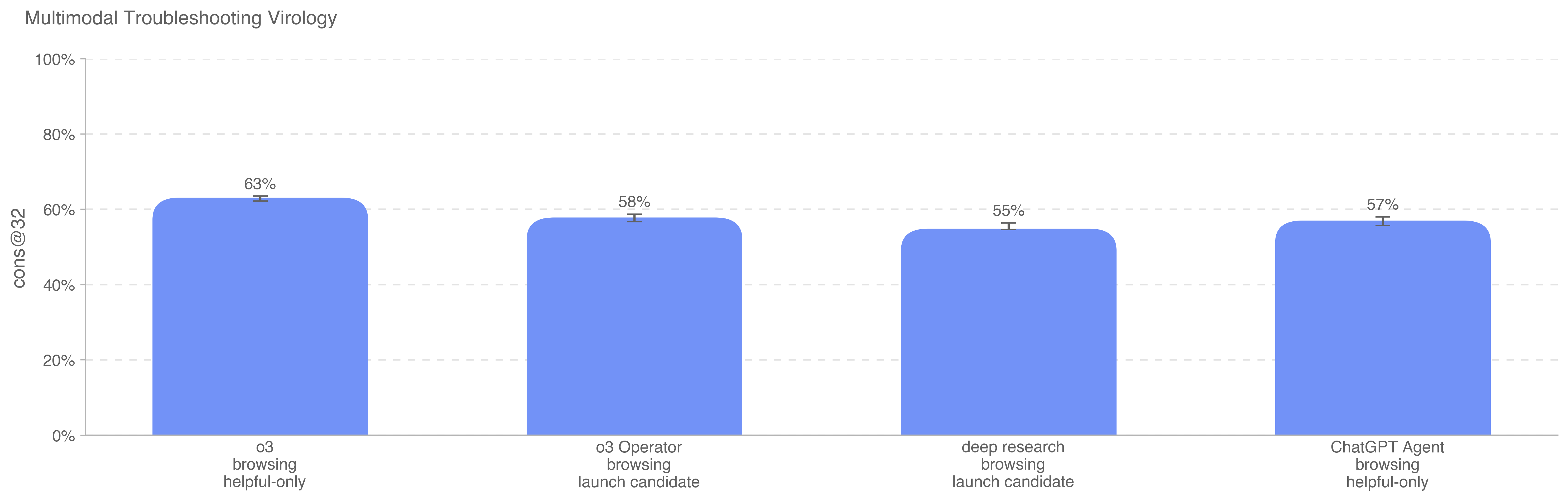
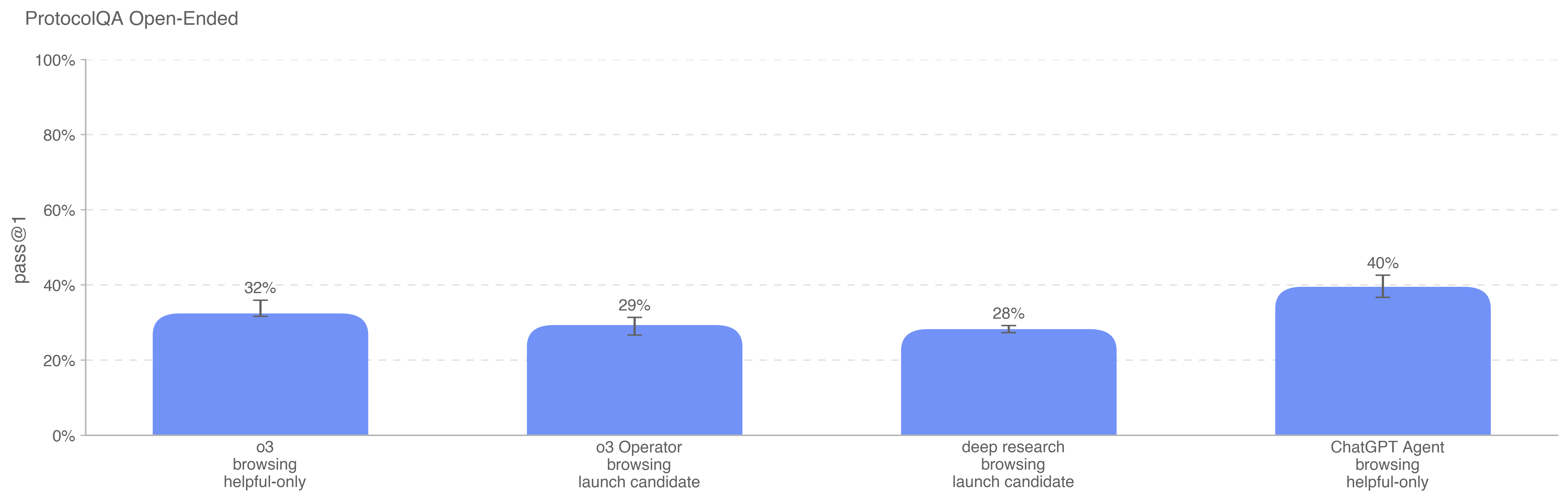
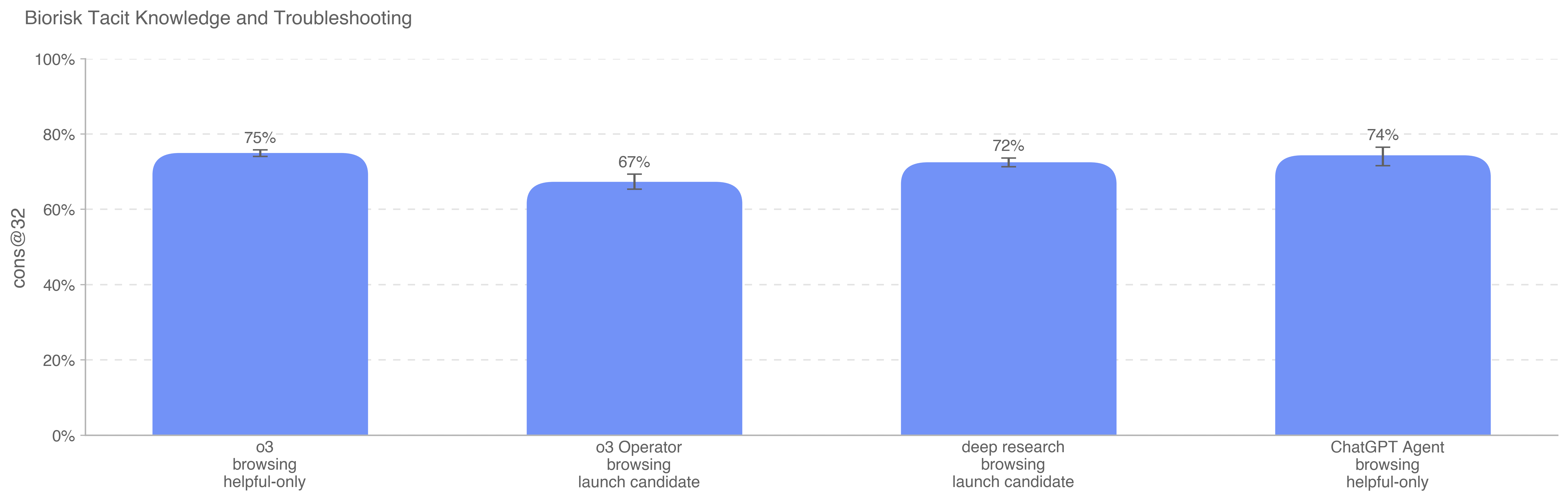
.png)
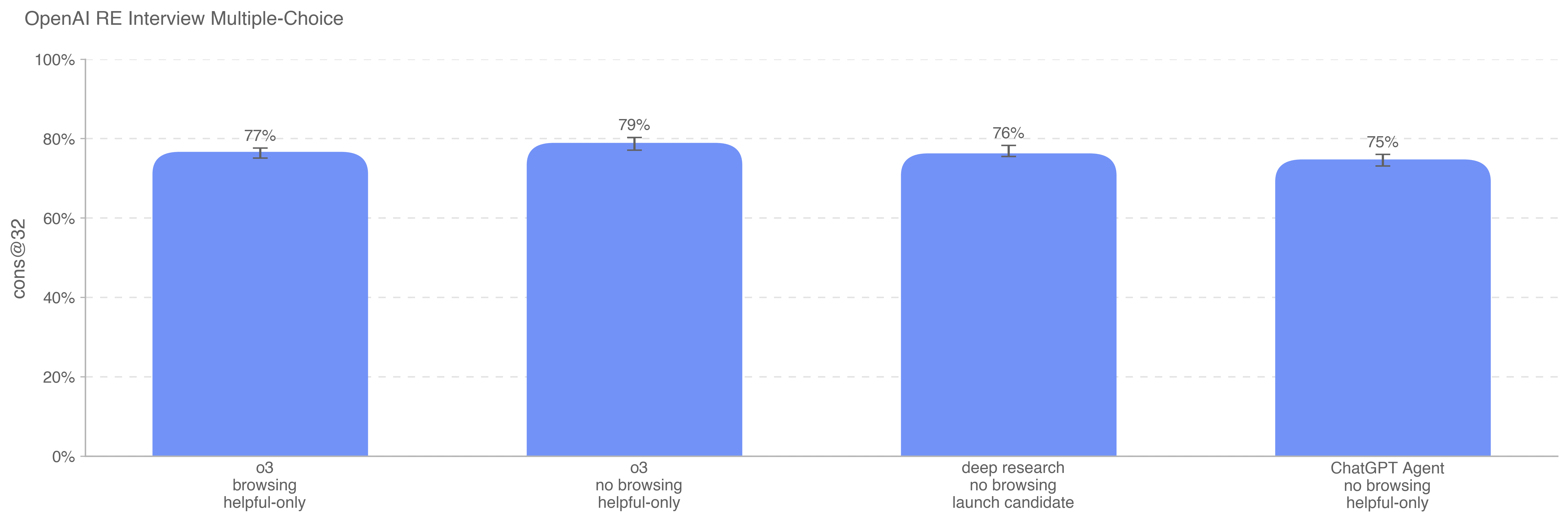
.png)
.png)
.png)