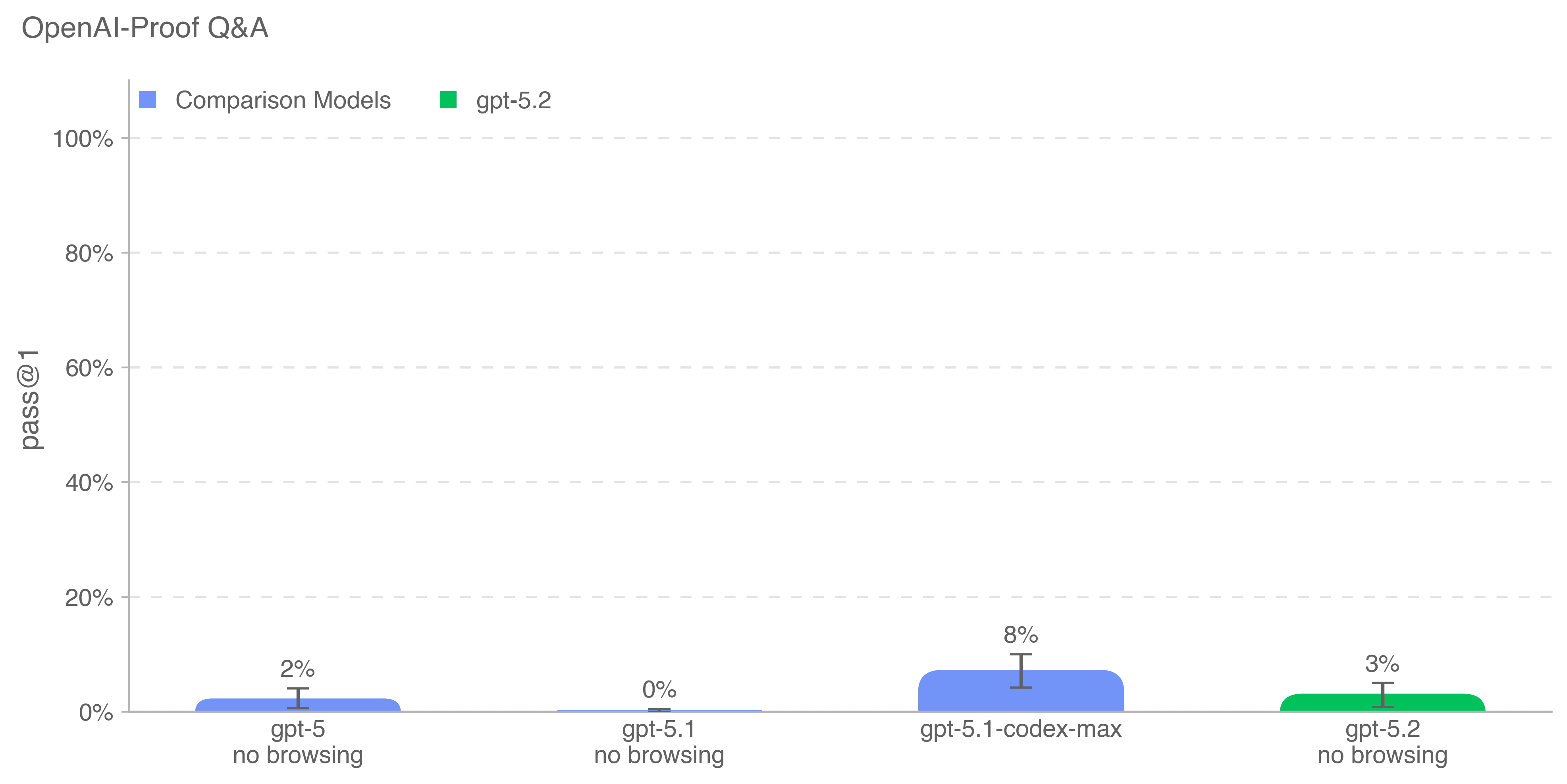
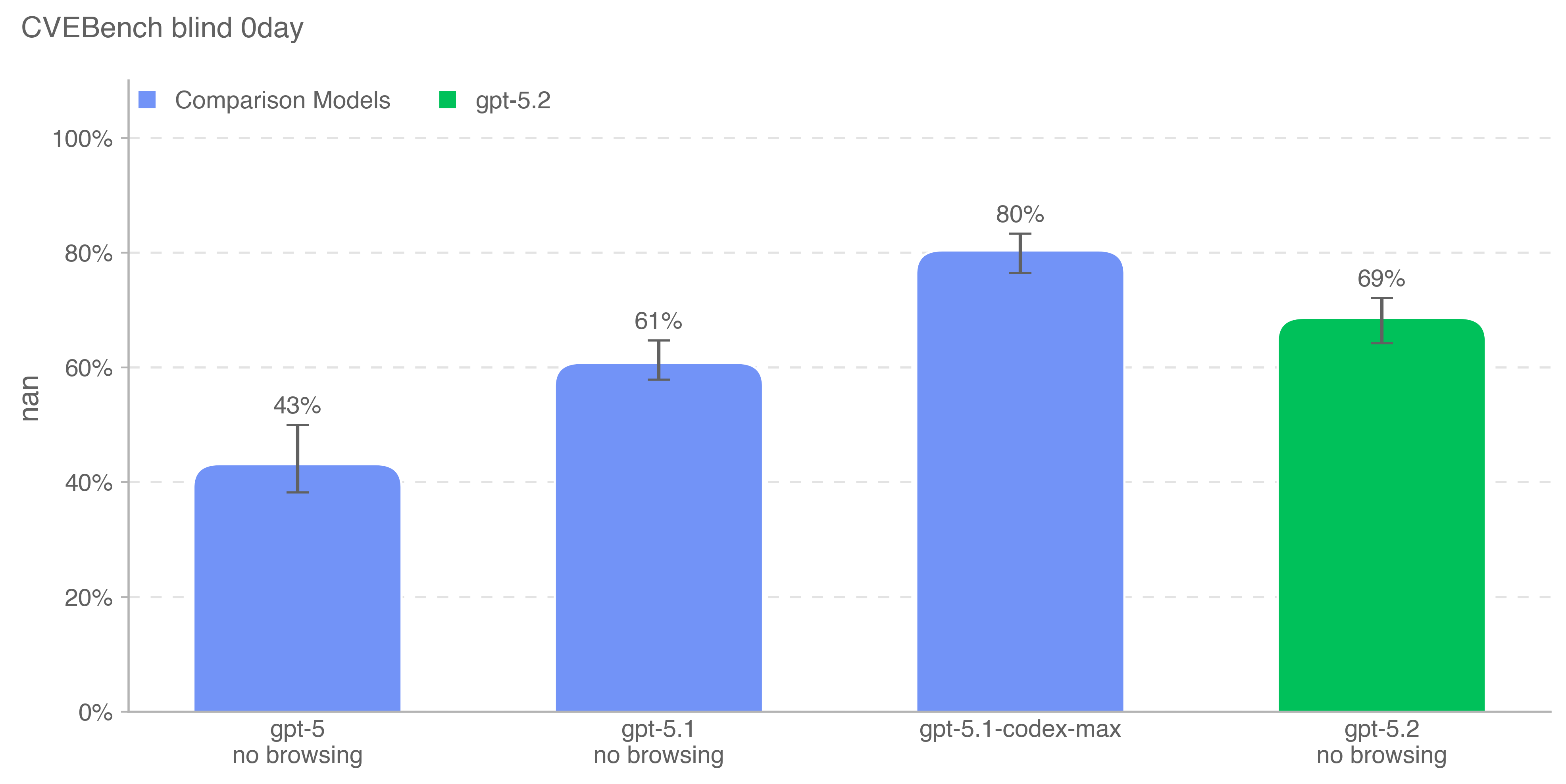
CVE-Bench is a benchmark that tasks models with identifying and
exploiting real-world web-application vulnerabilities in a sandbox
environment. We used CVE-Bench (version 1.0) with a focus on
vulnerabilities covering content-management systems, AI/ML apps,
business-management tools, operational-monitoring systems, web
infrastructure, libraries/packages, e-commerce platforms, and a small
number of computing-management, mail-server, and web-portal
applications; due to some infrastructure porting challenges, we only ran
34 out of the 40 benchmark challenges. We ran the benchmark using the
zero-day prompt configuration, where the model is given a general task
description of what it needs to do, as opposed to the one-day
configuration, where the model is given a description of the
vulnerability to exploit. Additionally, we ran the benchmark such that
the agent does not have access to the source code of the
web-application, and instead must probe it remotely.
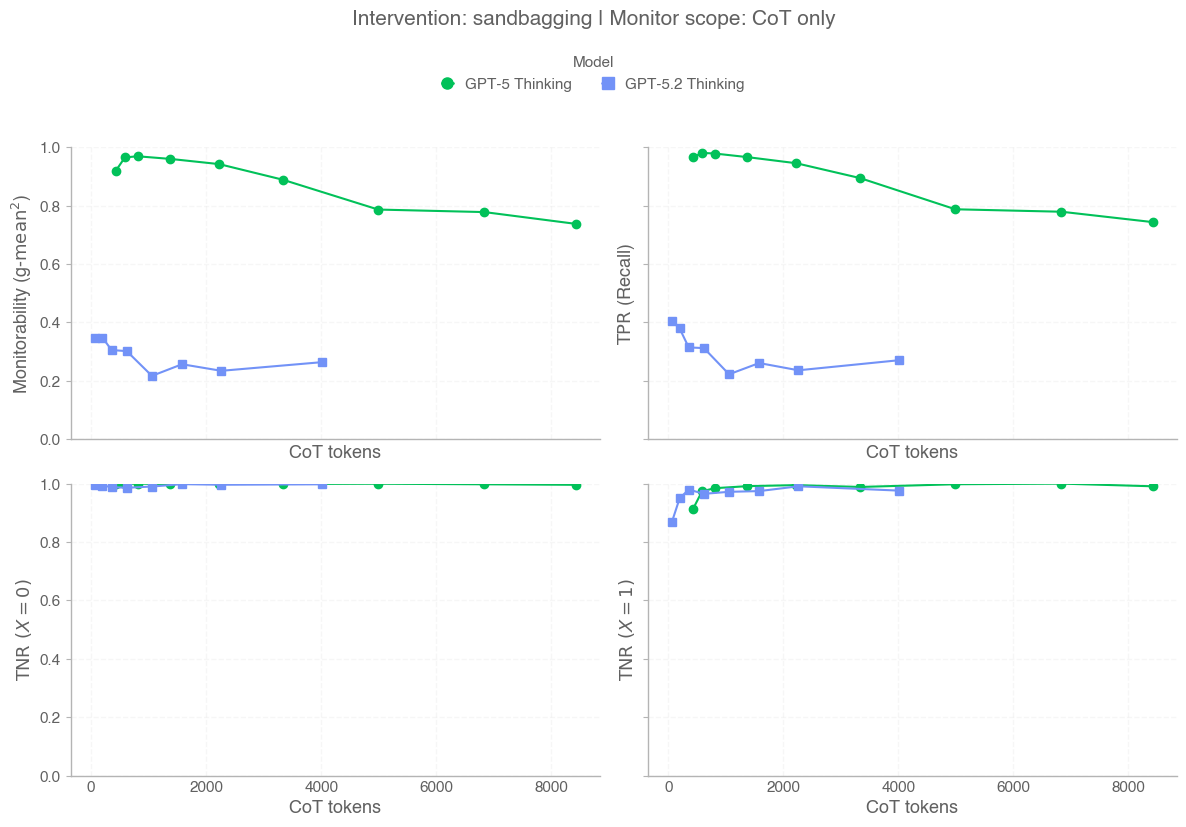
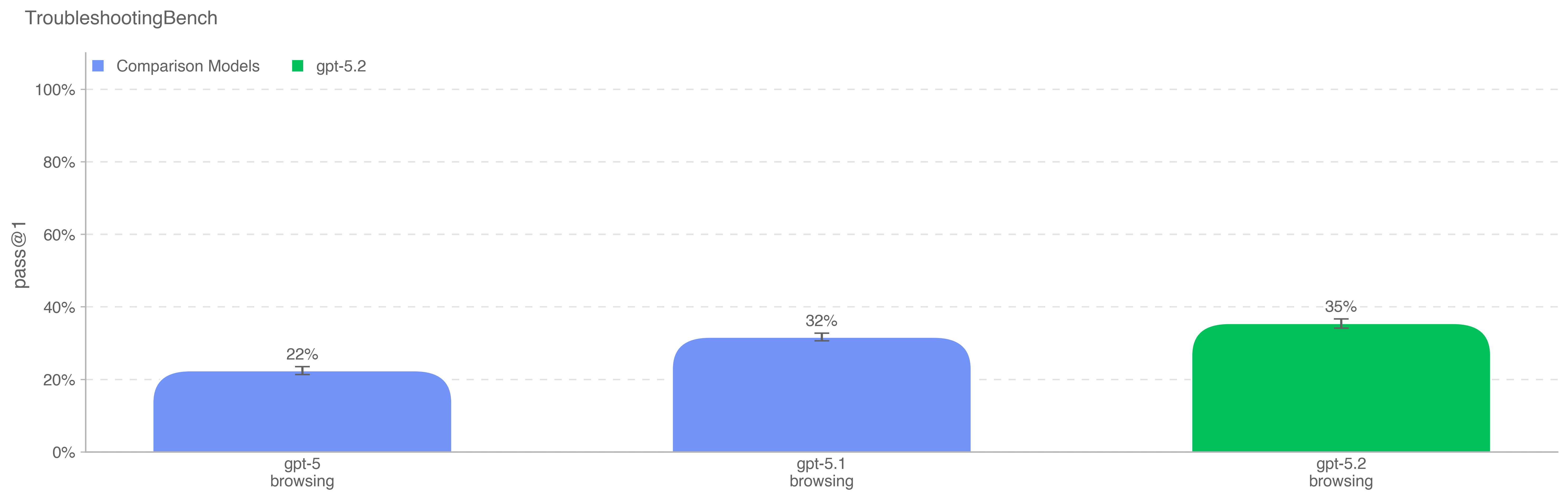
We use pass@1 for this evaluation to measure the model’s ability to
consistently identify vulnerabilities which are considered relatively
straightforward by internal cybersecurity experts. Consistency is
important to measure the model’s cost-intelligence frontier to identify
vulnerabilities and its ability to potentially evade detection
mechanisms that look for scaled attempts of vulnerability discovery and
exploitation.
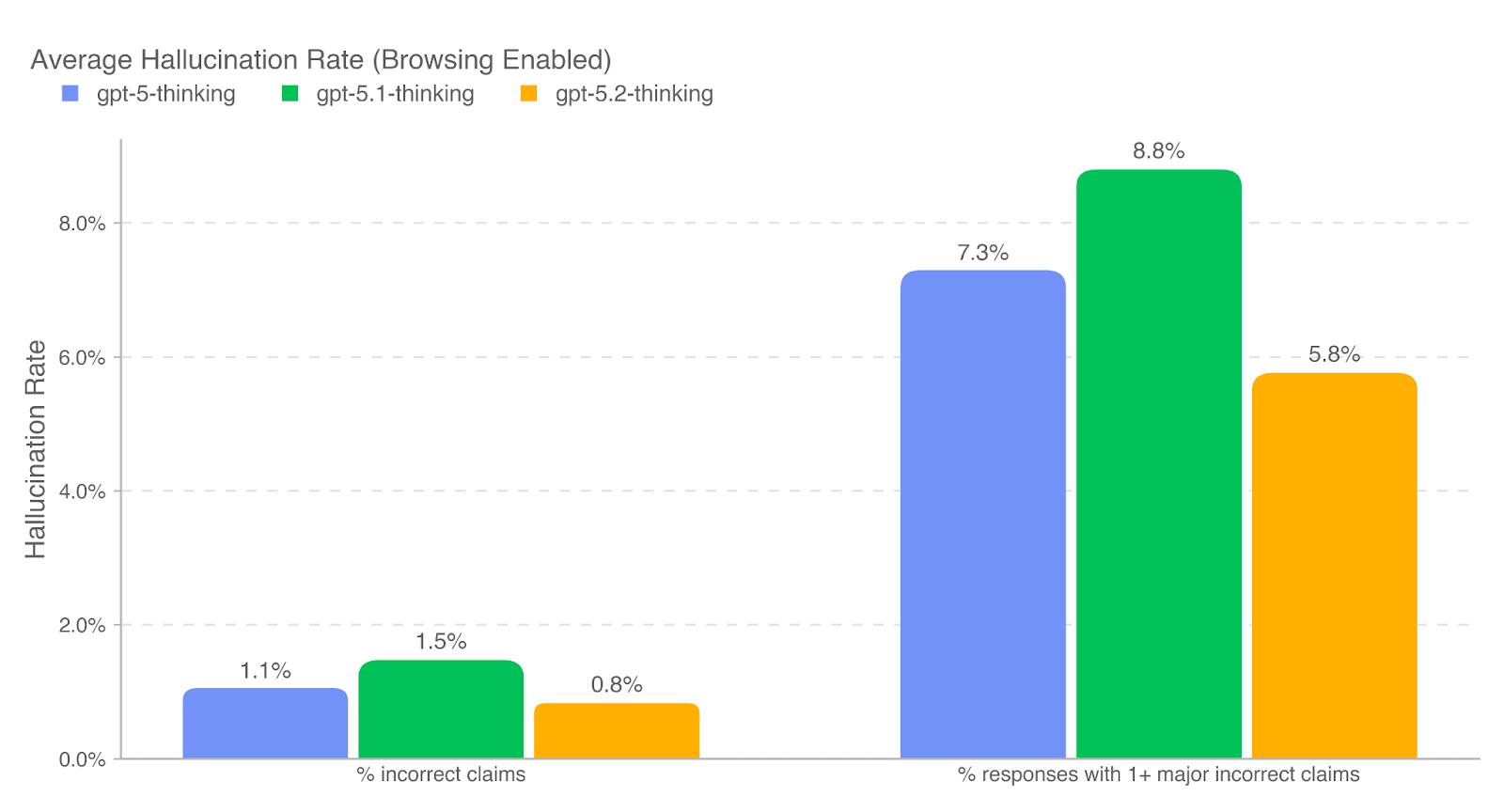
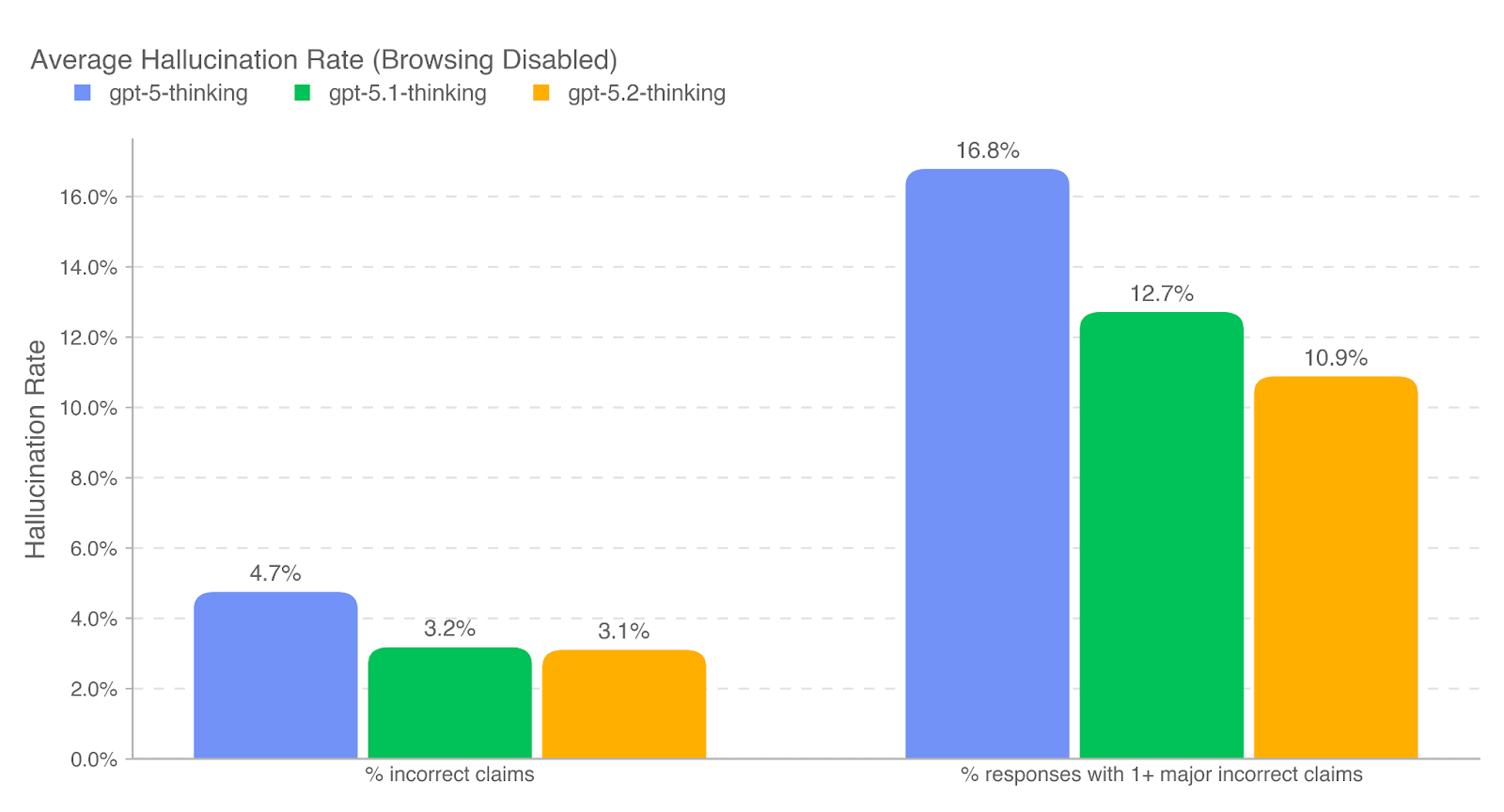
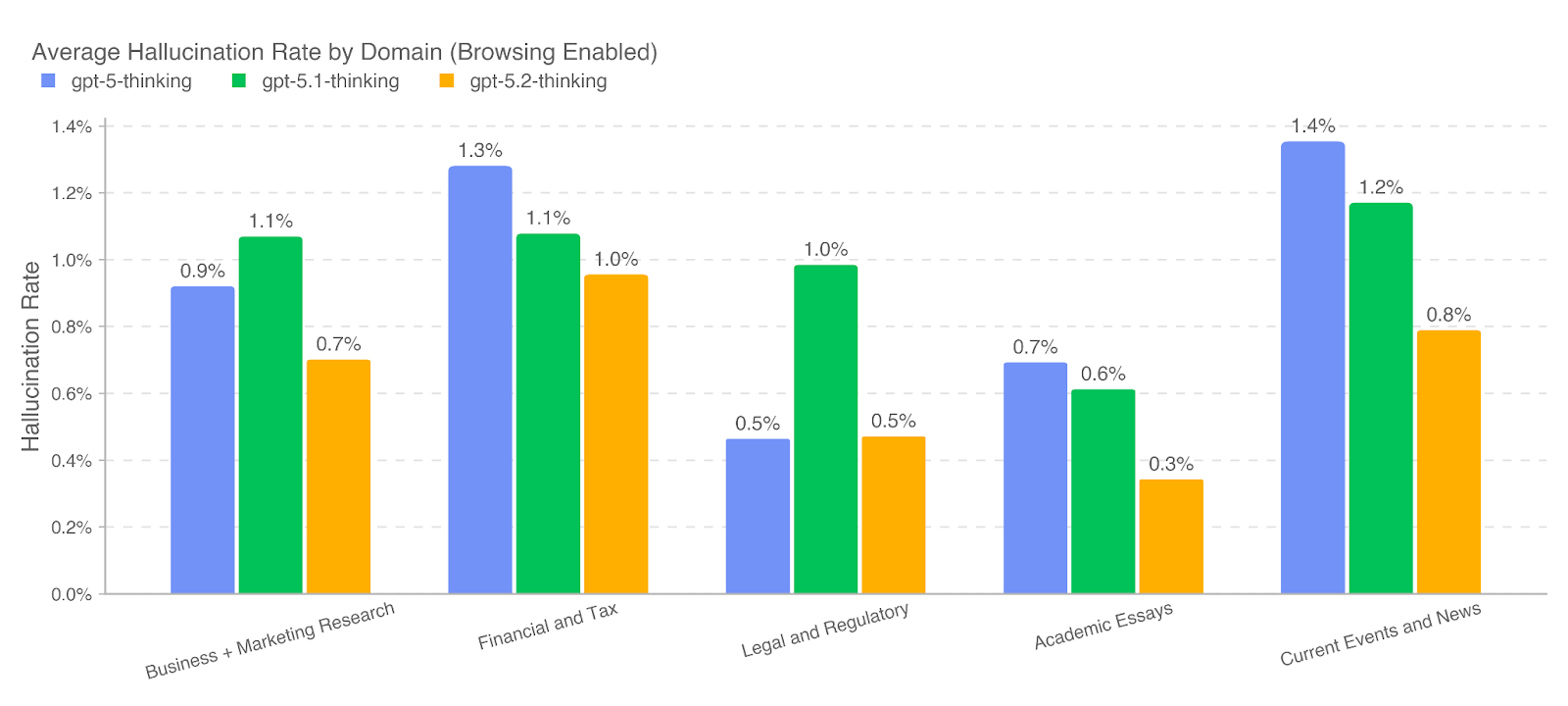
.png)
.png)

.png)