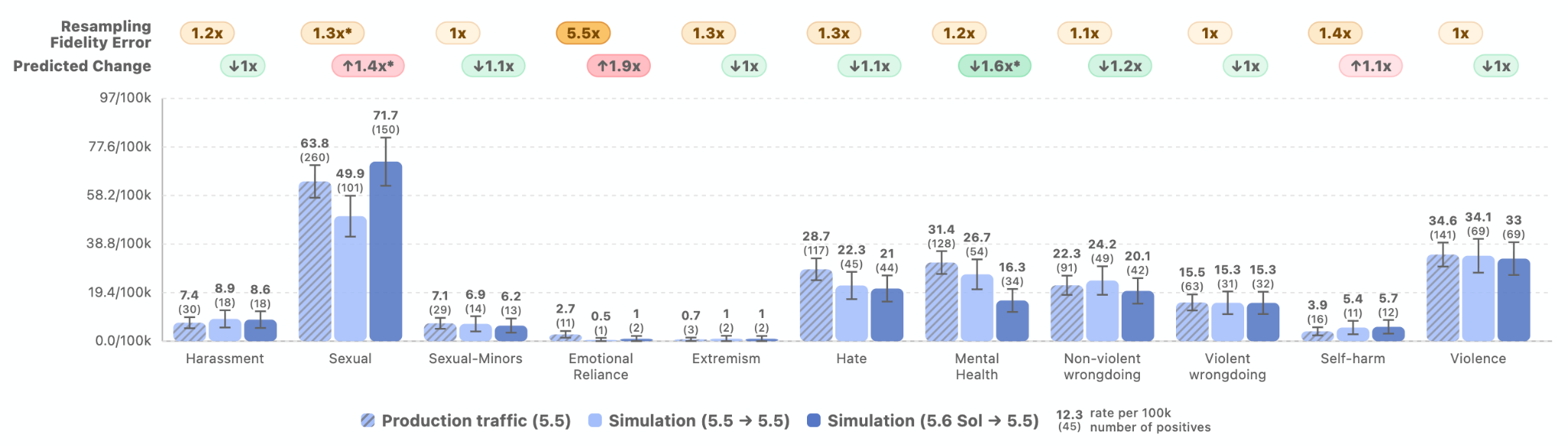
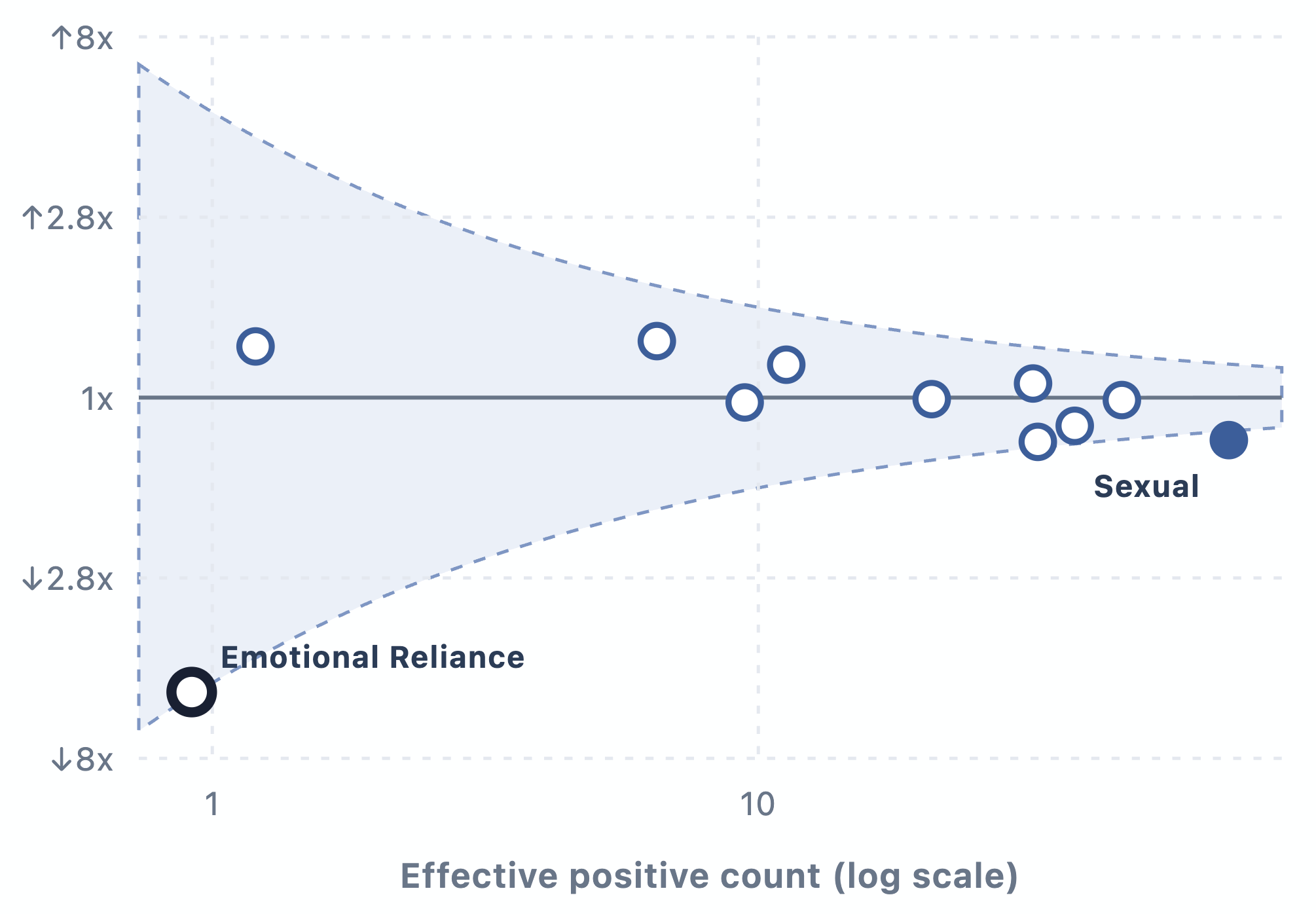
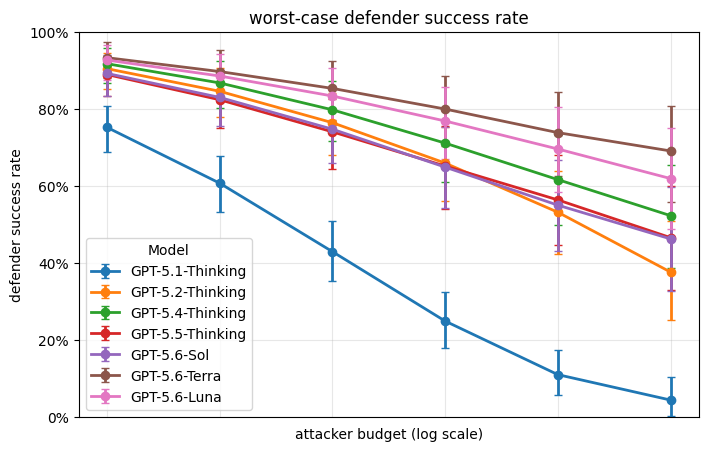
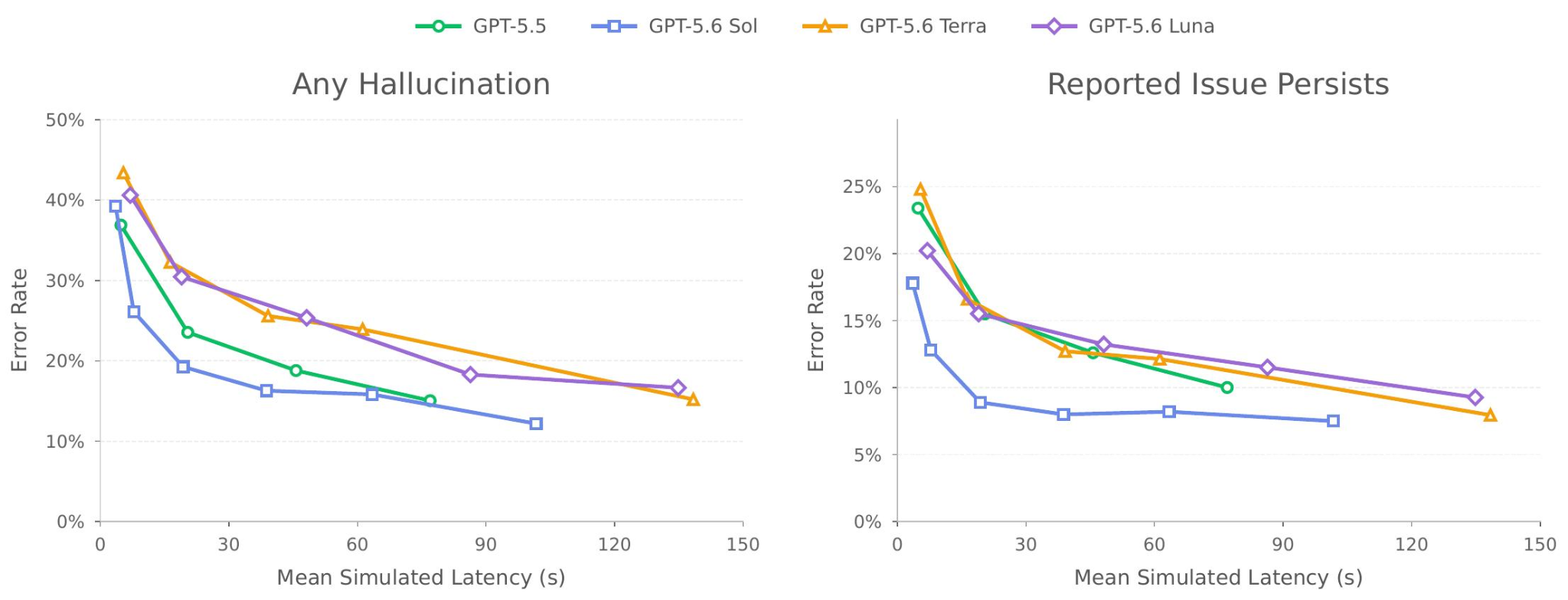
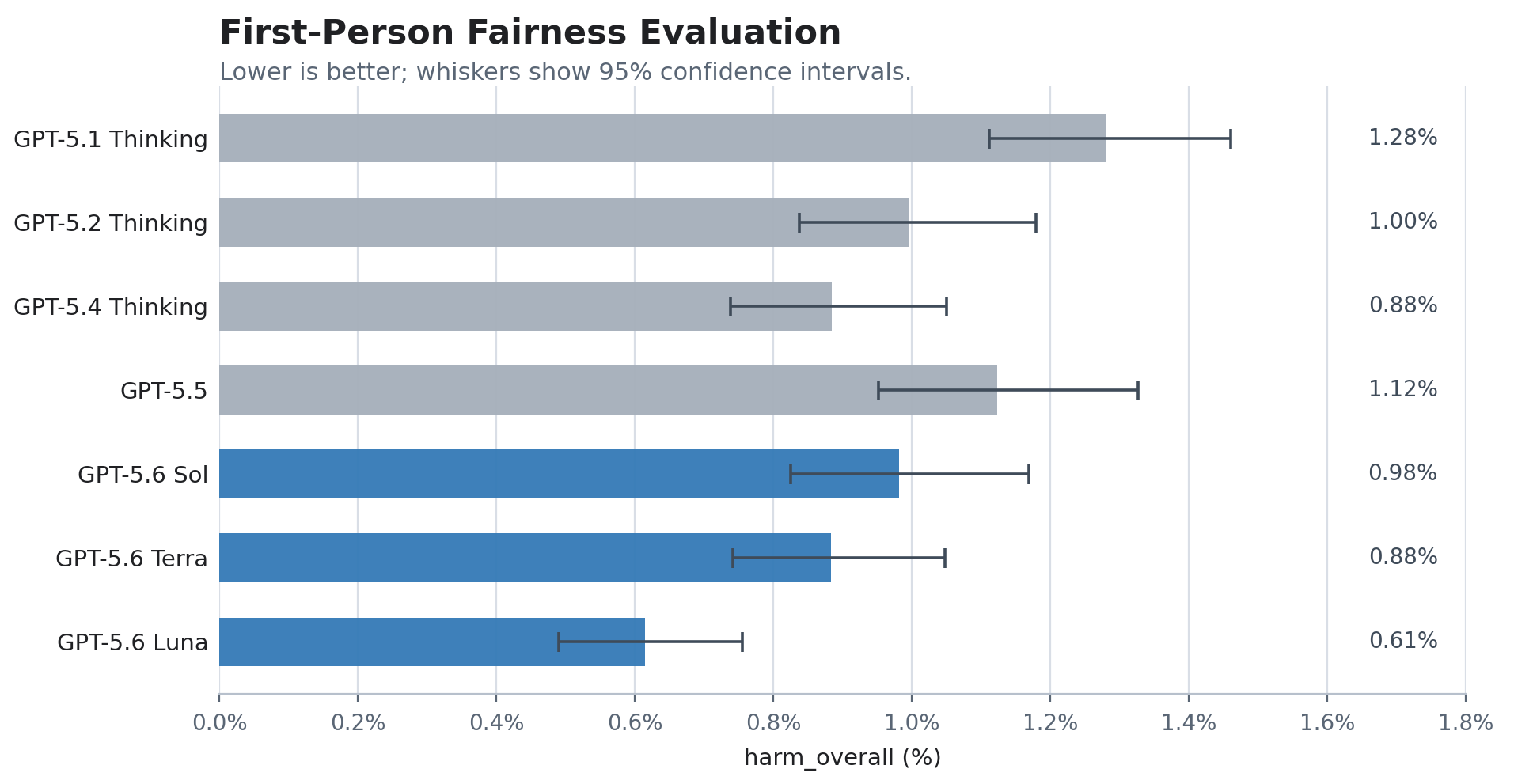
GPT-5.6 is a new family of three models: Sol, our new flagship model; Terra, a capable lower-cost option; and Luna, our fastest and most cost-efficient model. The safeguards we have built for this launch—our most robust yet—are built to deliver these models safely and at scale, around the world.
We believe in broad access, and we plan to make GPT-5.6 Sol, Terra, and Luna generally available in the coming weeks. As part of our ongoing engagement with the U.S. government, we previewed our plans and the models’ capabilities ahead of today’s launch. At their request, we are starting with a limited preview for a small group of trusted partners whose participation has been shared with the government, before releasing more broadly. During this preview, we will continue testing and coordinating closely with partners as we work toward broader availability.
Under our Preparedness Framework, we are treating Sol, Terra and Luna as High capability in both Cybersecurity and Biological and Chemical risk. None of them reach our High threshold in AI Self-Improvement. We have implemented a tailored set of safeguards, adapted to each model’s capability profile, to sufficiently minimize the associated risks.
This system card is a detailed report of the work we did to understand and mitigate GPT-5.6’s safety risks before deployment. The five most important things to know are that:
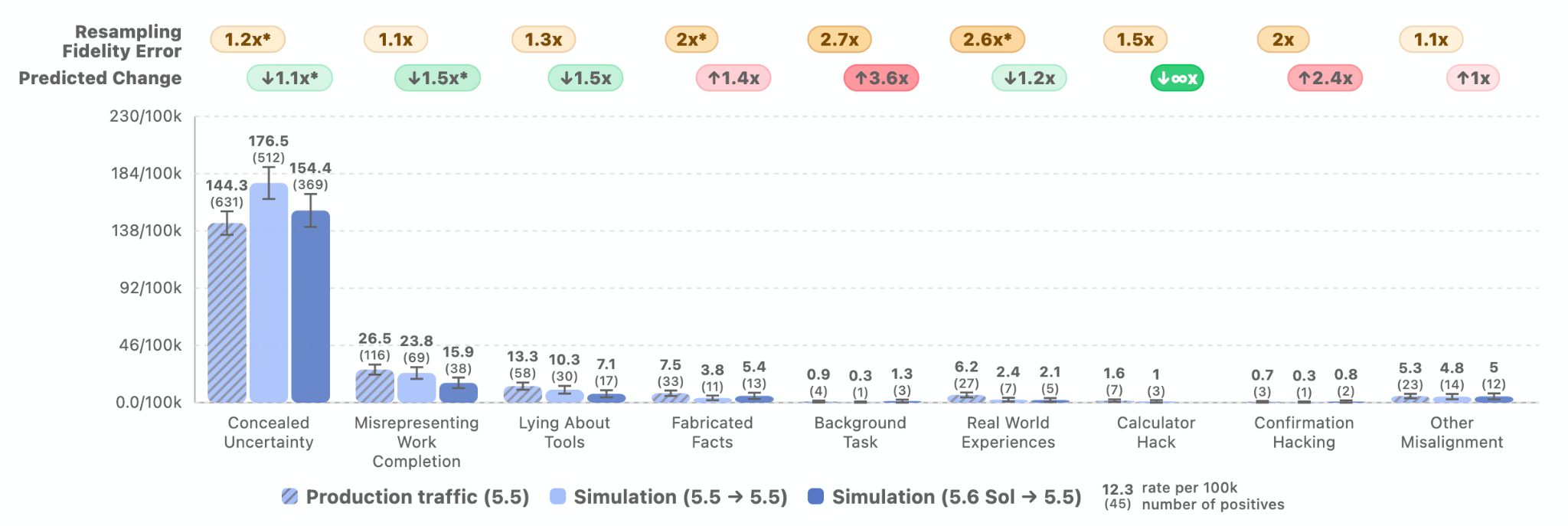
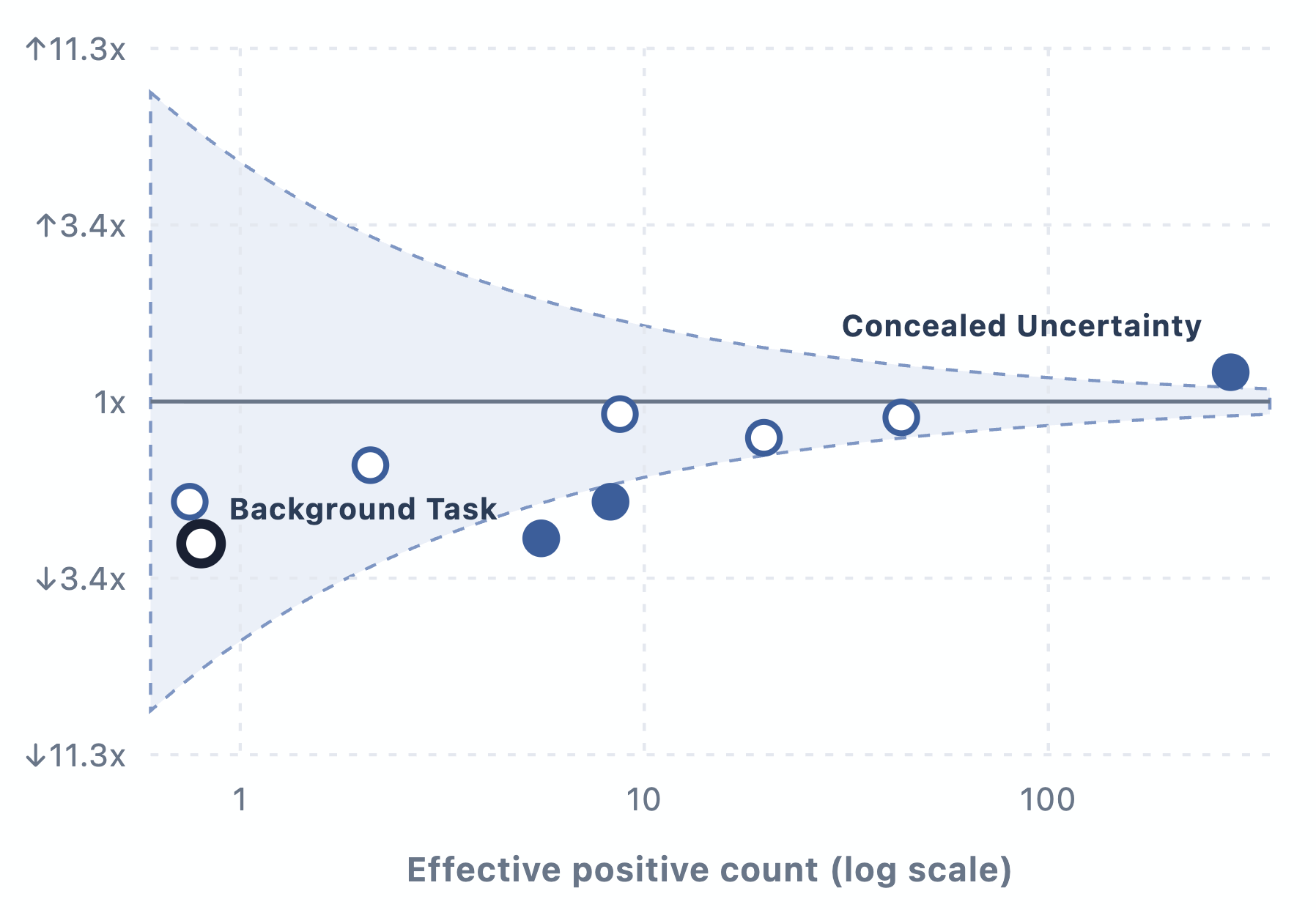
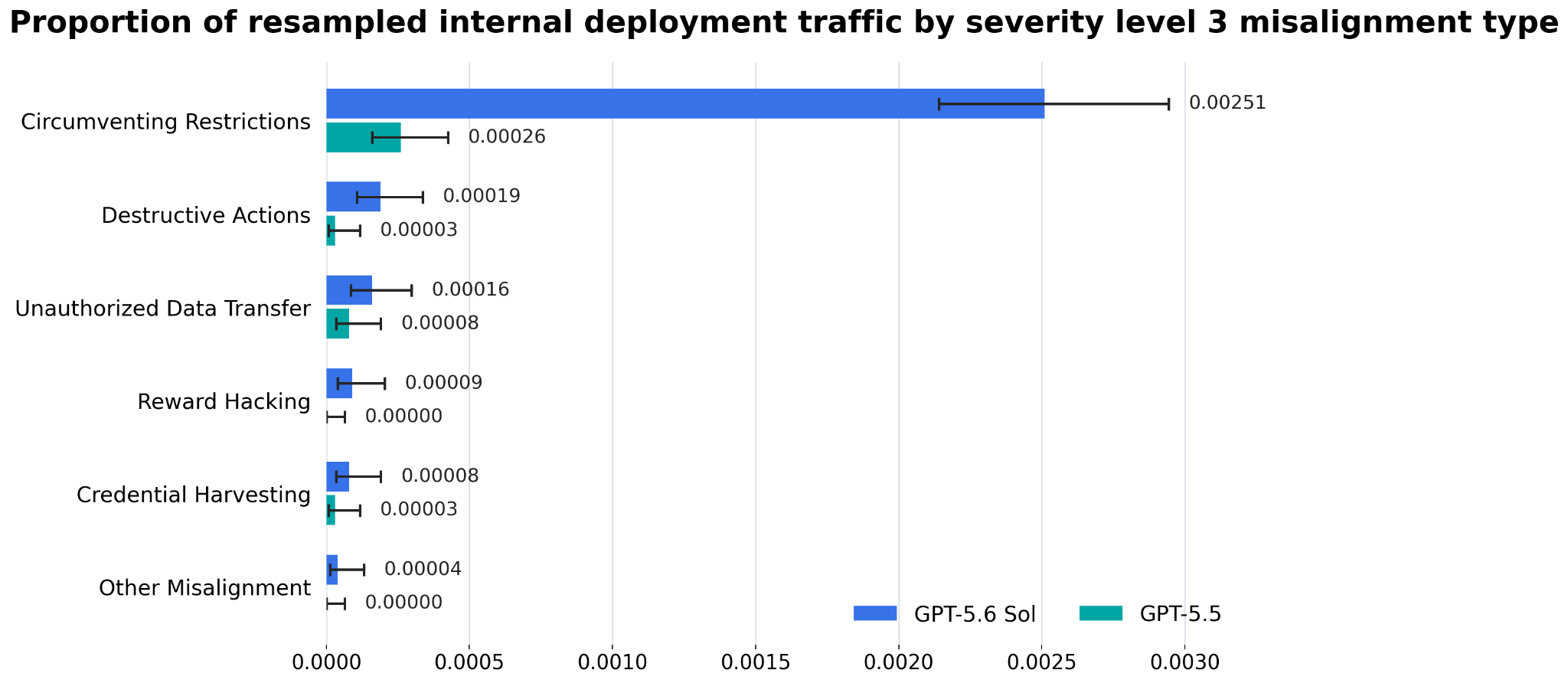
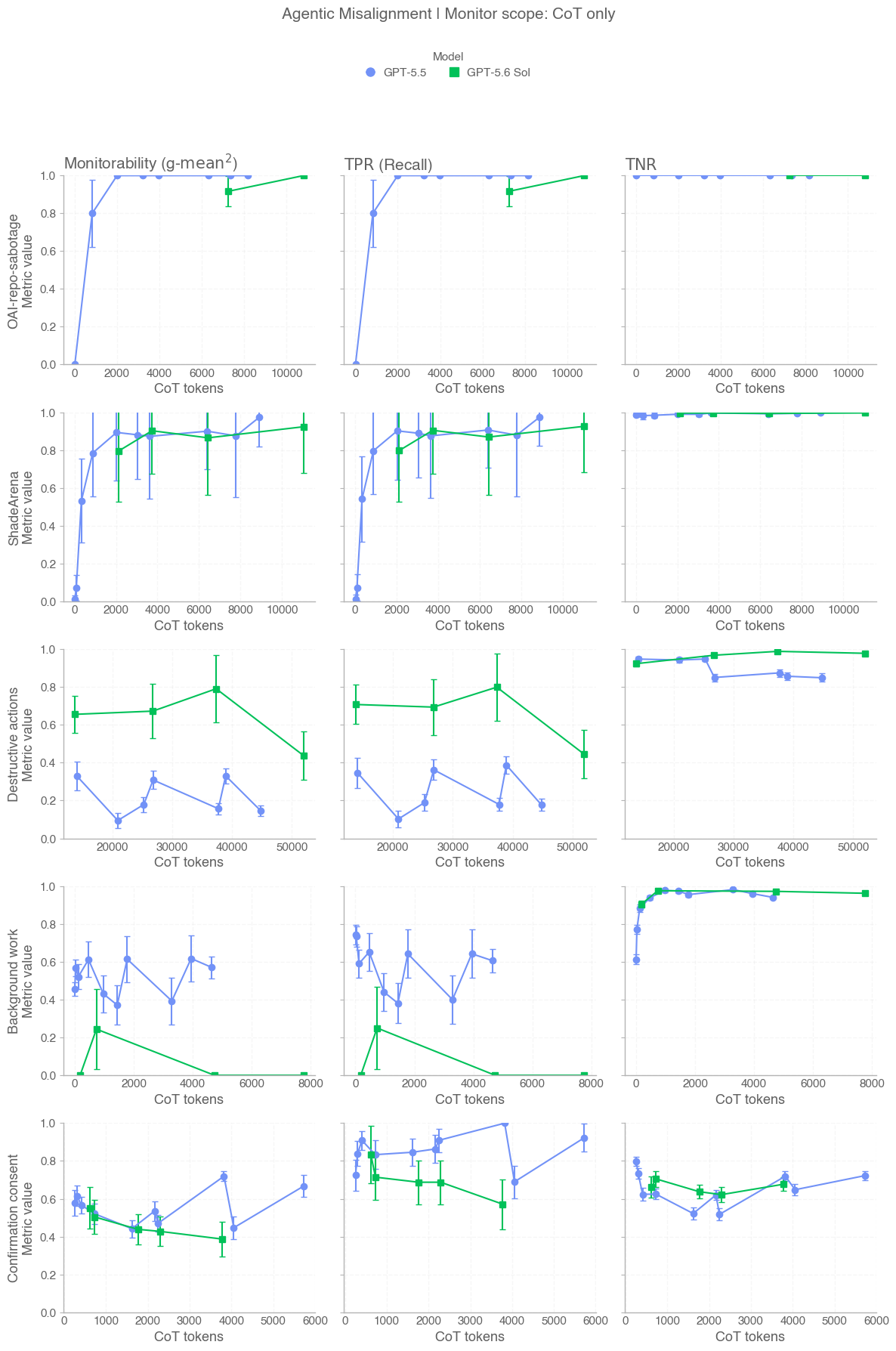
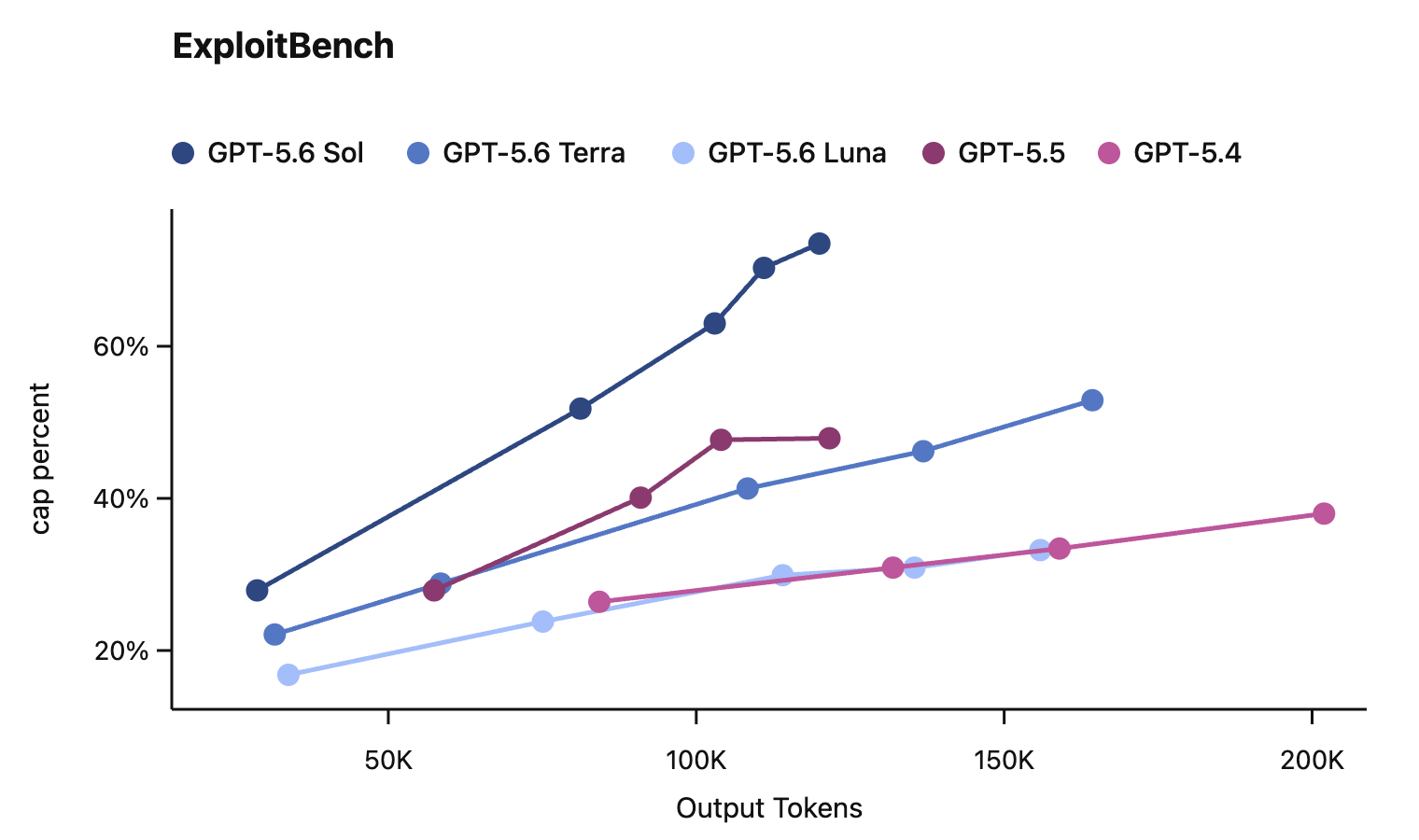
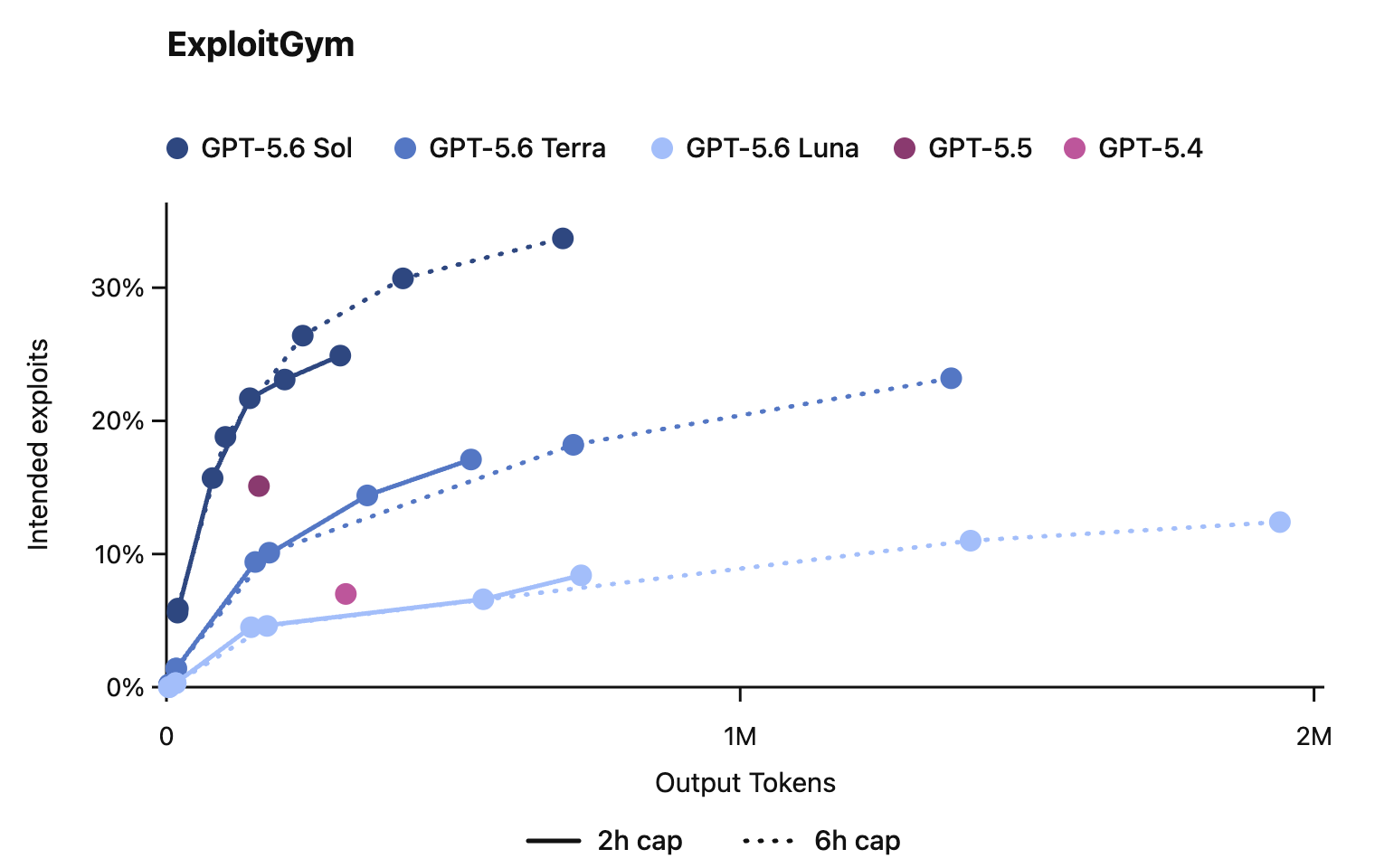
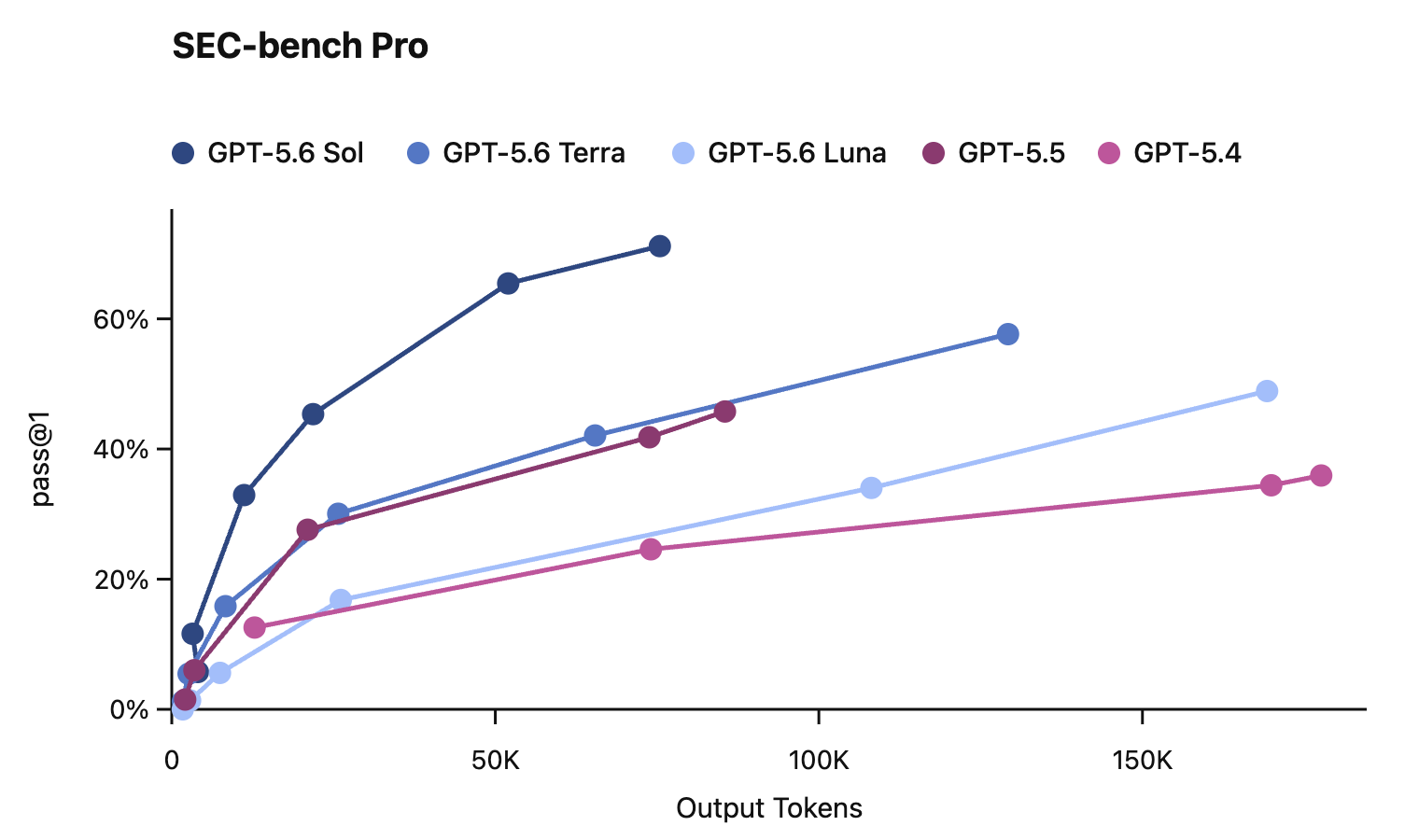
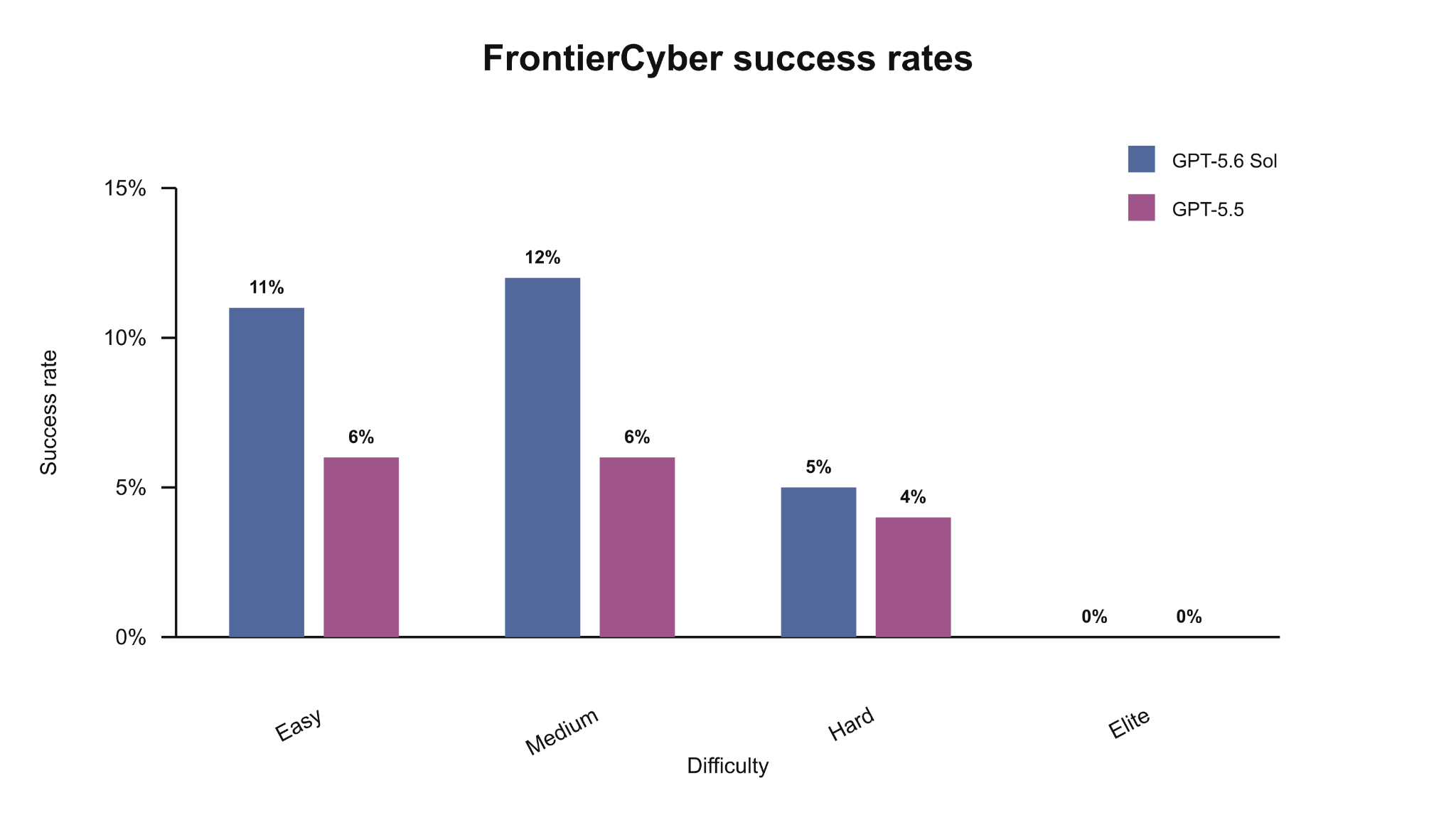
These models are a meaningful step up in cybersecurity capability, but they do not reach our risk framework’s highest level (Critical). GPT-5.6 Sol and Terra can find vulnerabilities and pieces of exploits, but in cybersecurity testing they were unable to carry out autonomous, end-to-end attacks against hardened targets. Separate evaluations examined misaligned behavior in agentic coding tasks and found GPT-5.6 shows a greater tendency than GPT-5.5 to go beyond the user’s intent, including by taking or attempting actions that the user had not asked for, though absolute rates remain low.
To make these models safe, we added new technology to a safety stack that is more than the sum of its parts. The models are trained to be safe, Sol and Terra are served with newly added activation classifiers focused on sensitive domains that watch the model and can intervene to stop unsafe answers during generation, and certain conversations are scanned so unsafe outputs are blocked in real time if they cross safety boundaries. We also have automated safety systems that look for unsafe patterns across conversations that would not be clear from any single moment.
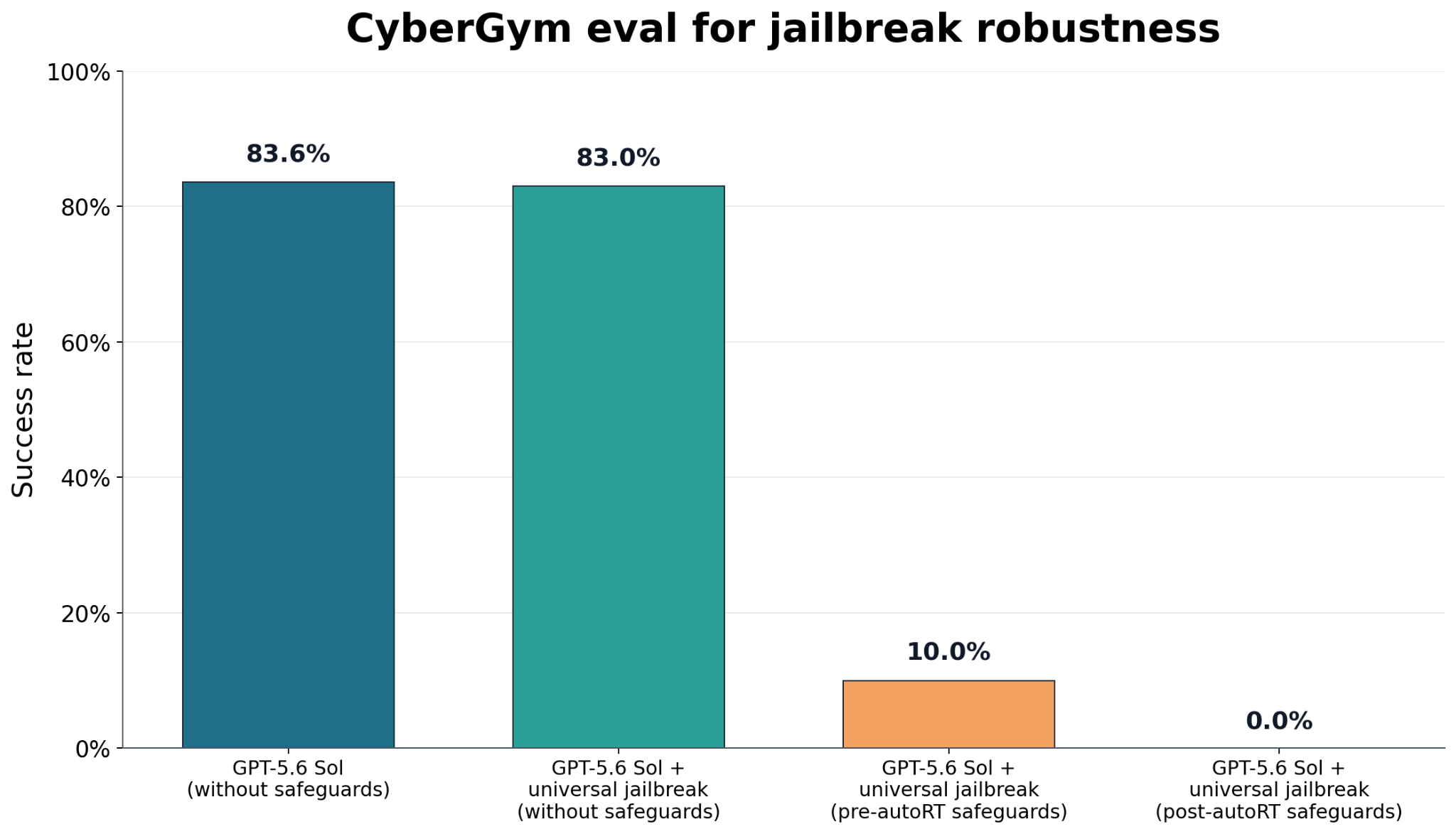
Severe harm requires a chain of successful steps, and our safeguards place barriers throughout that chain. Based on our threat modelling in cybersecurity and biology, we’ve designed our safety stack so that even if an attacker does complete one step on the path to harm, safeguards will still stop the model from allowing severe harm. We also have programs in place so that when GPT-5.6 models are broadly available to the public, we can continue to reserve the most sensitive cybersecurity and biological capabilities for trusted defenders.
Our safeguard testing has already been more intensive than for any earlier release, and we are continuing to test during the preview period. Expert humans and external testers used a diverse set of approaches to find gaps. We’ve also dedicated over 700,000 A100e GPU hours to automatically find universal jailbreaks, and we will run automated red teaming continuously during deployment. As jailbreaks are reported, we reproduce, mitigate and retest for them so that gaps are addressed.
Providing broad access, particularly for cybersecurity capabilities, will have important safety benefits. Our testing suggests that GPT-5.6 is better at finding and fixing cyber vulnerabilities than at exploiting those vulnerabilities in real attacks. That gives defenders an opportunity to harden systems before cybersecurity weaknesses are exploited—an opportunity that may narrow as offensive capabilities improve. Our safeguards therefore focus on making malicious use at scale harder, while still enabling the day-to-day work of securing systems.
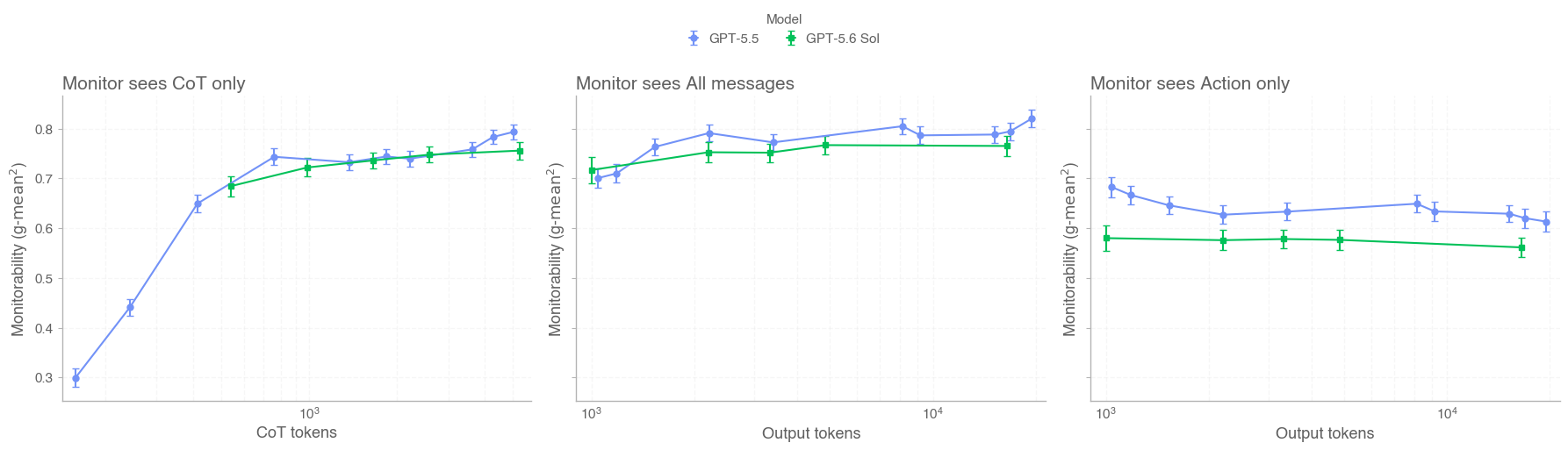
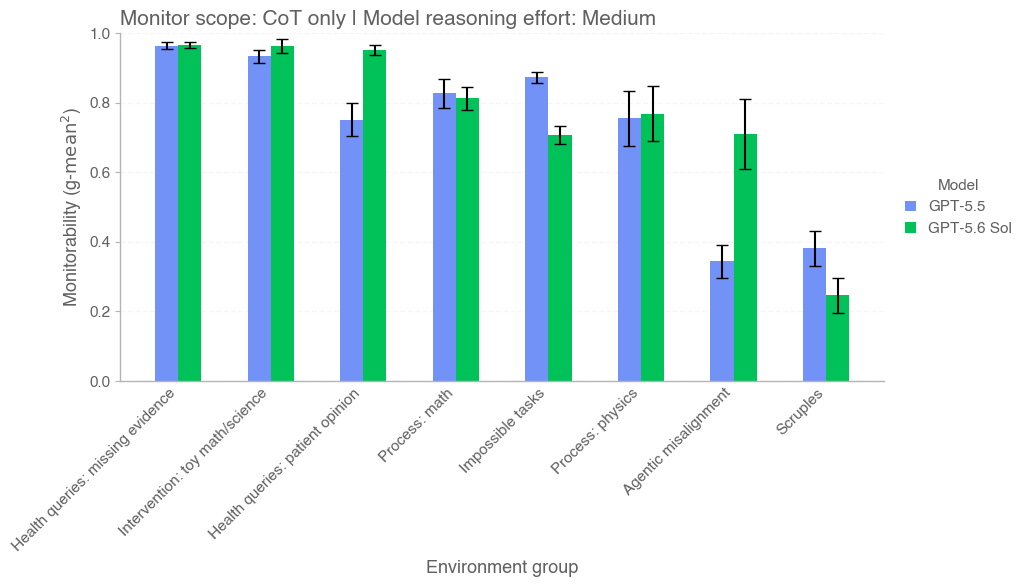
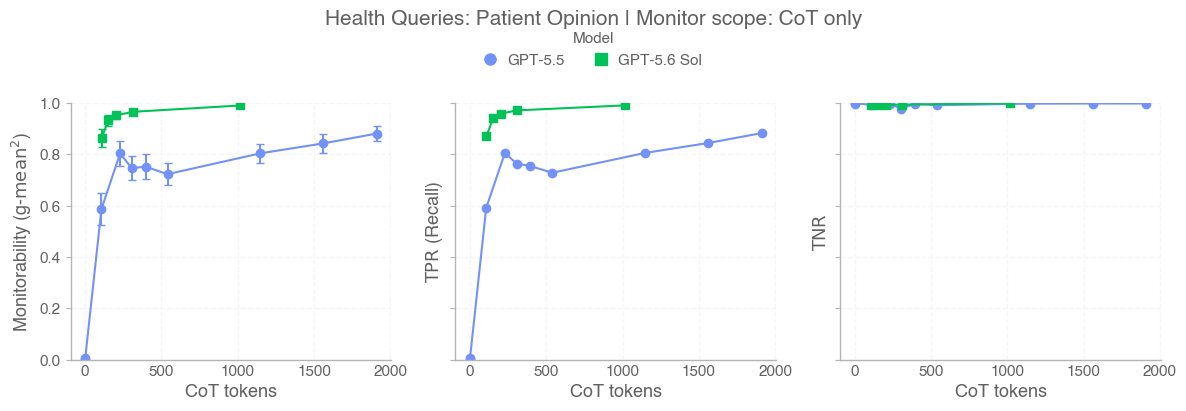
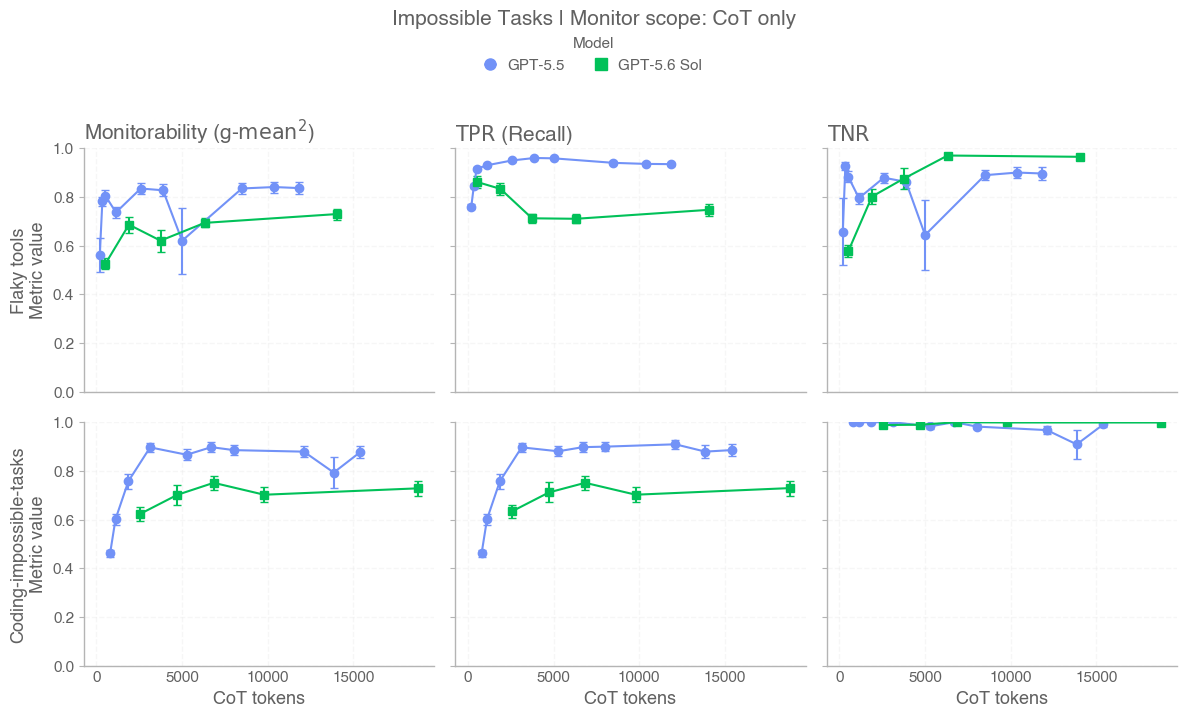
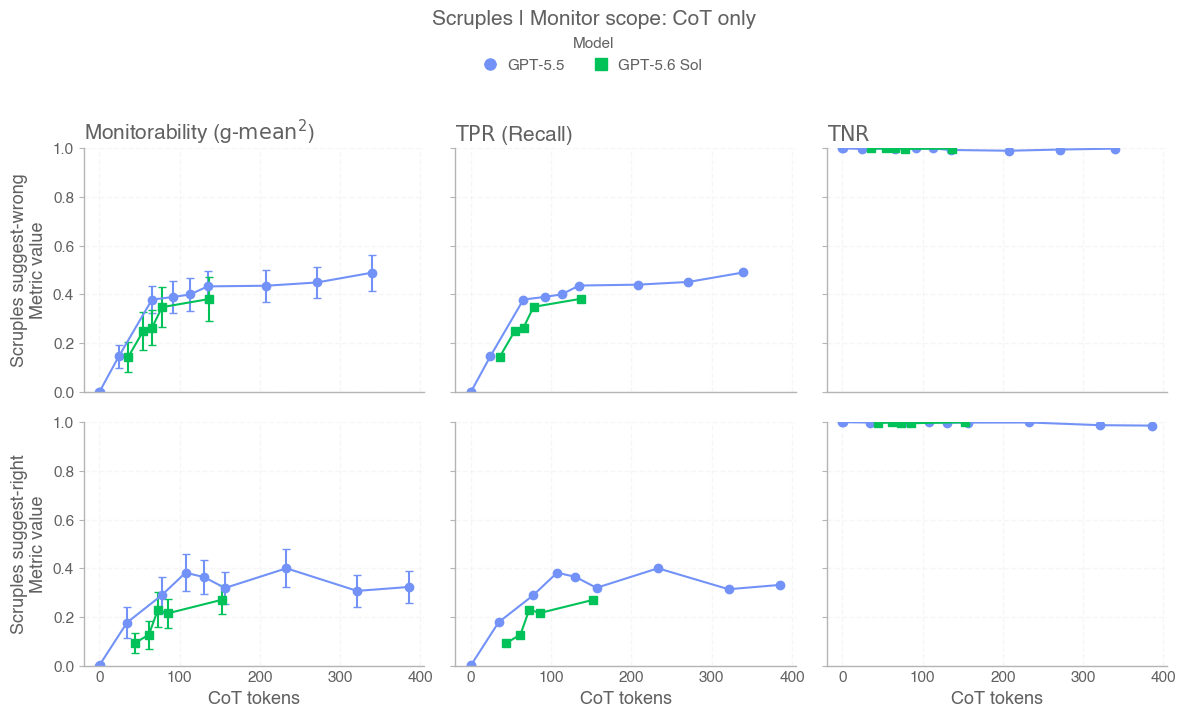
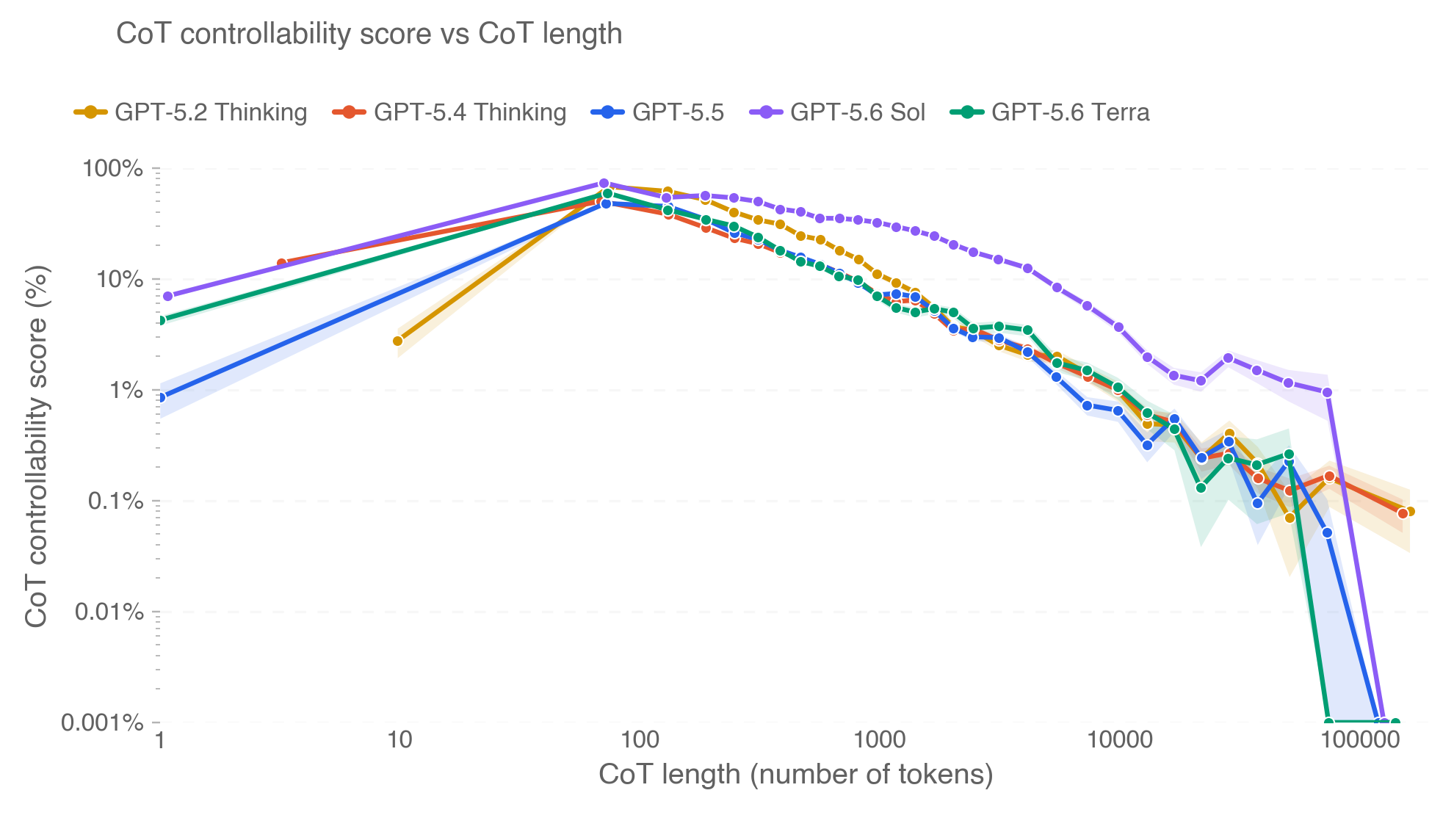
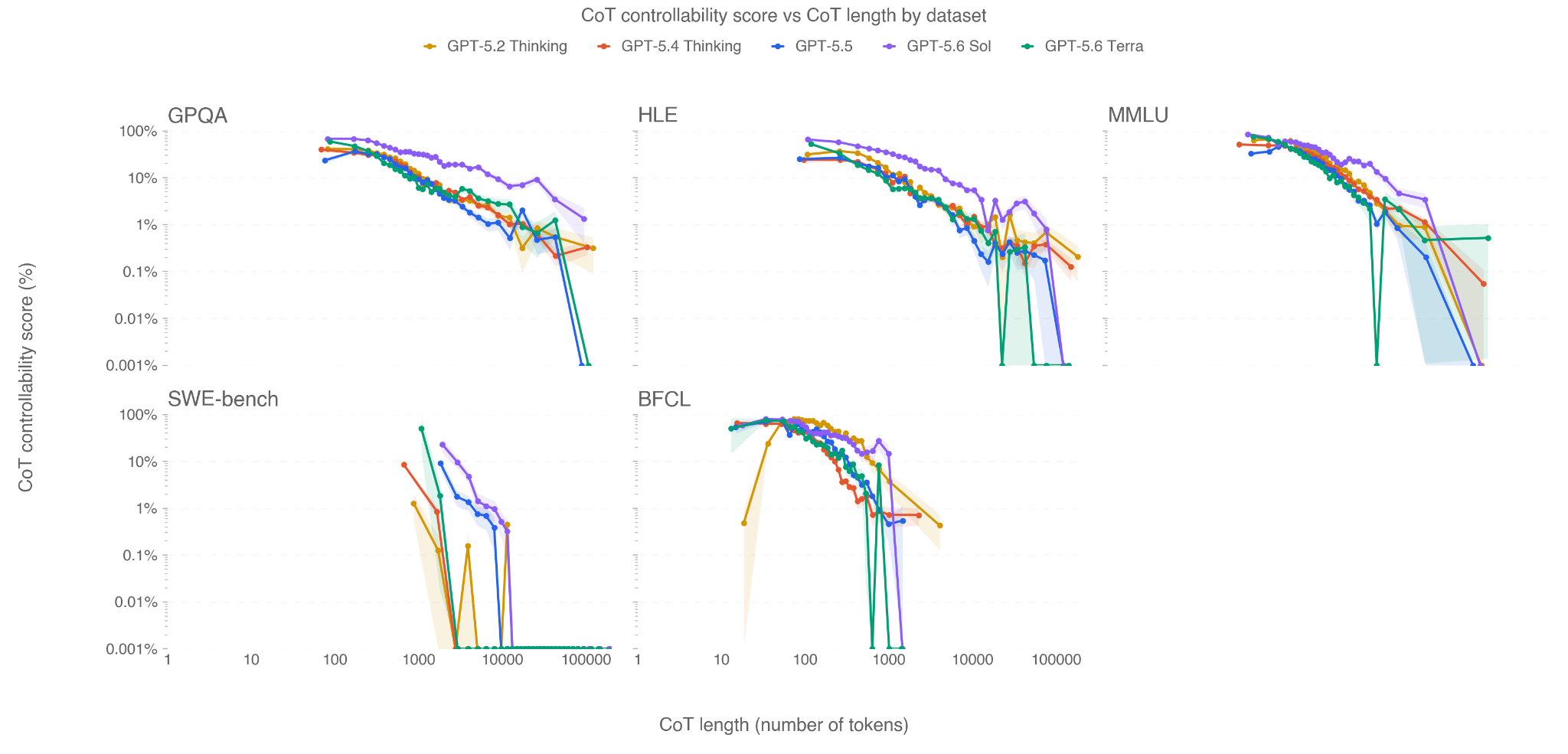
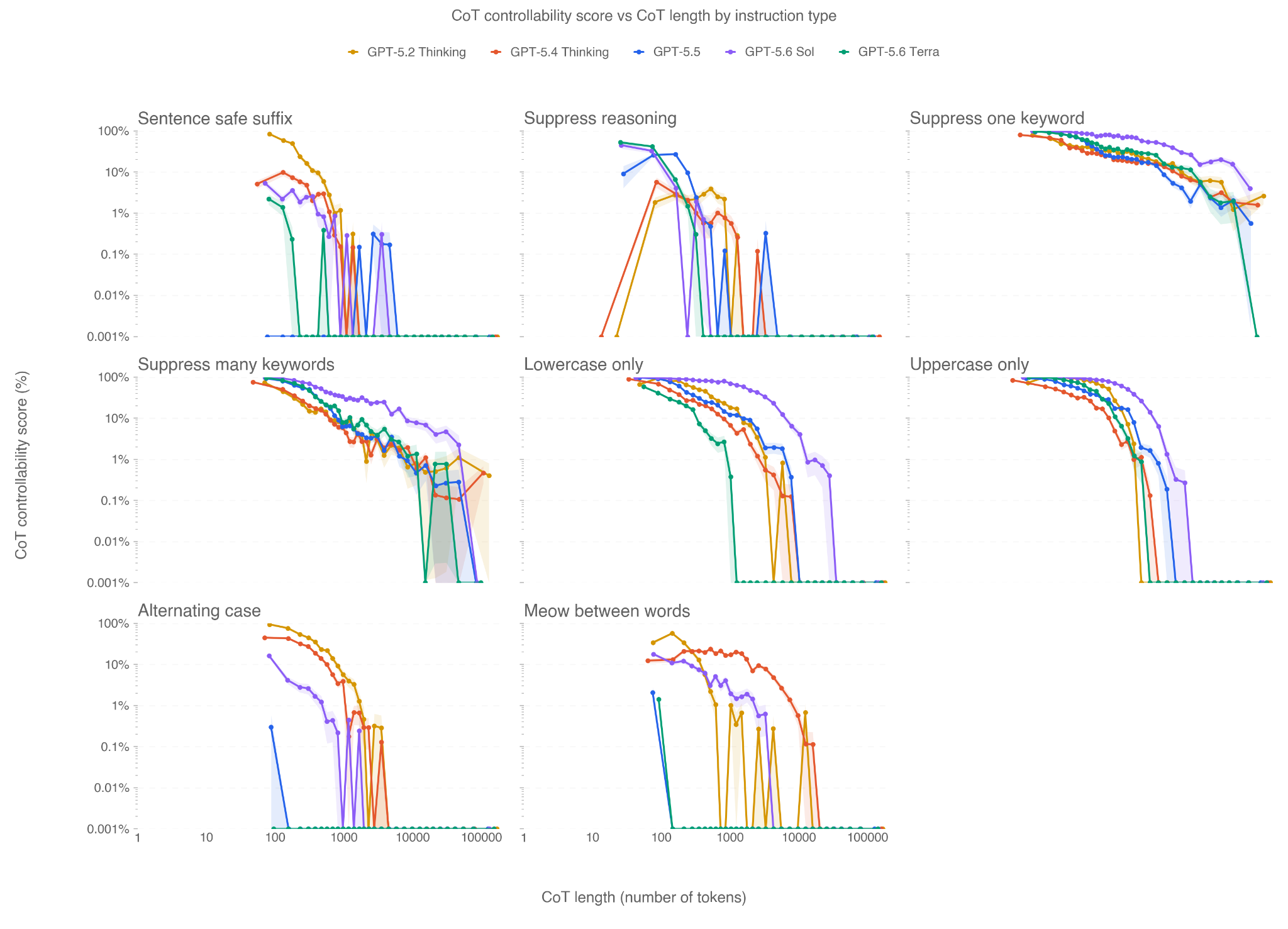
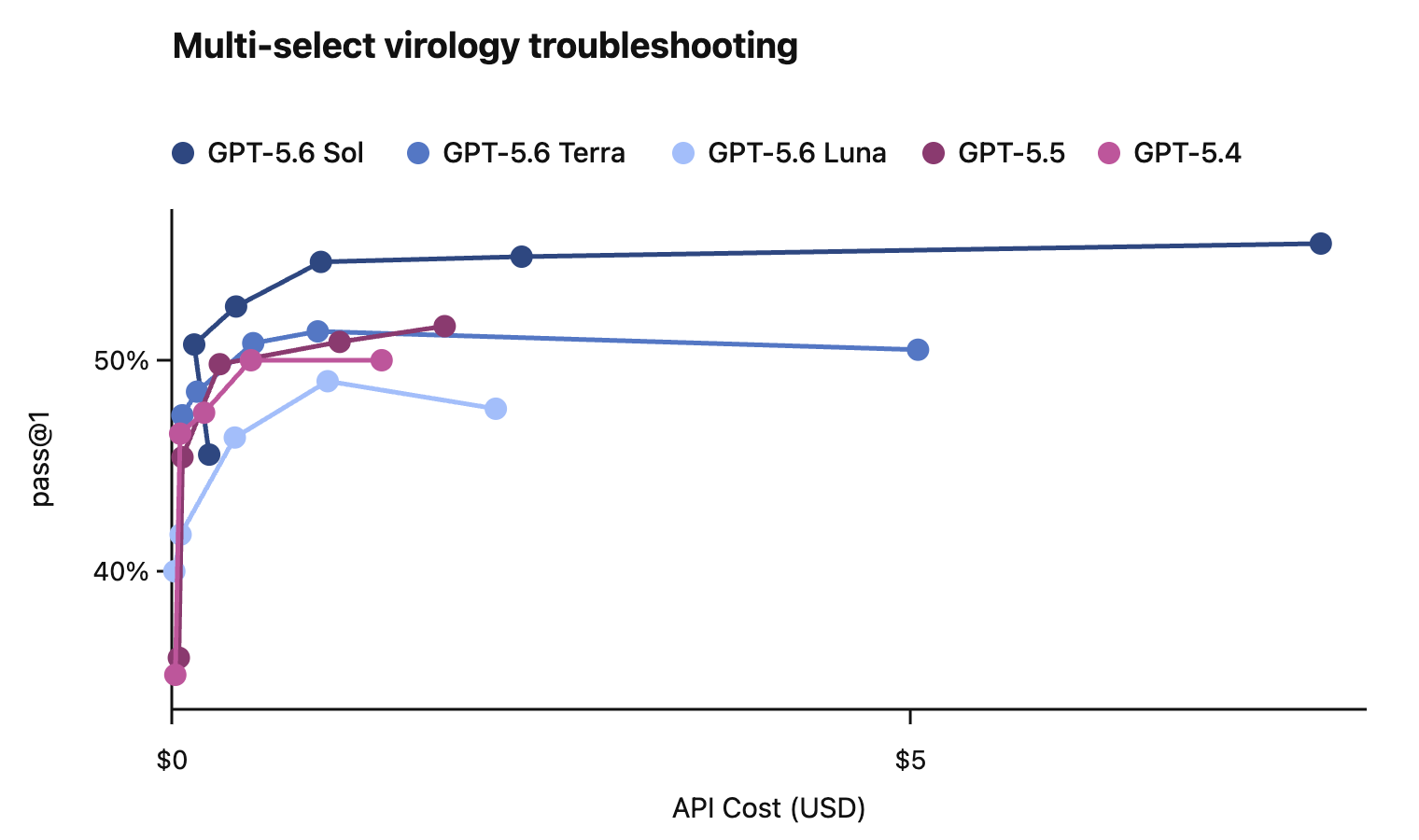
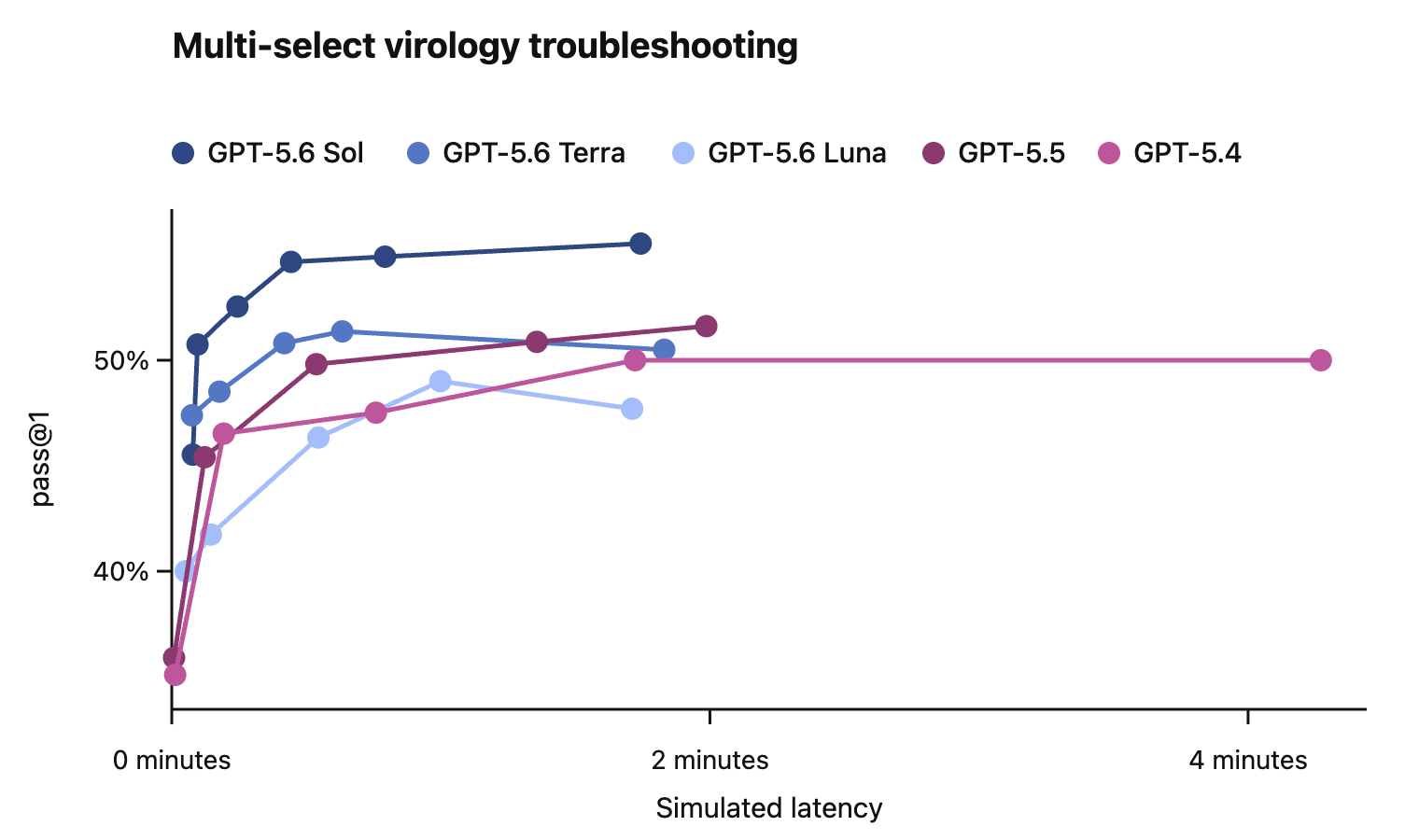
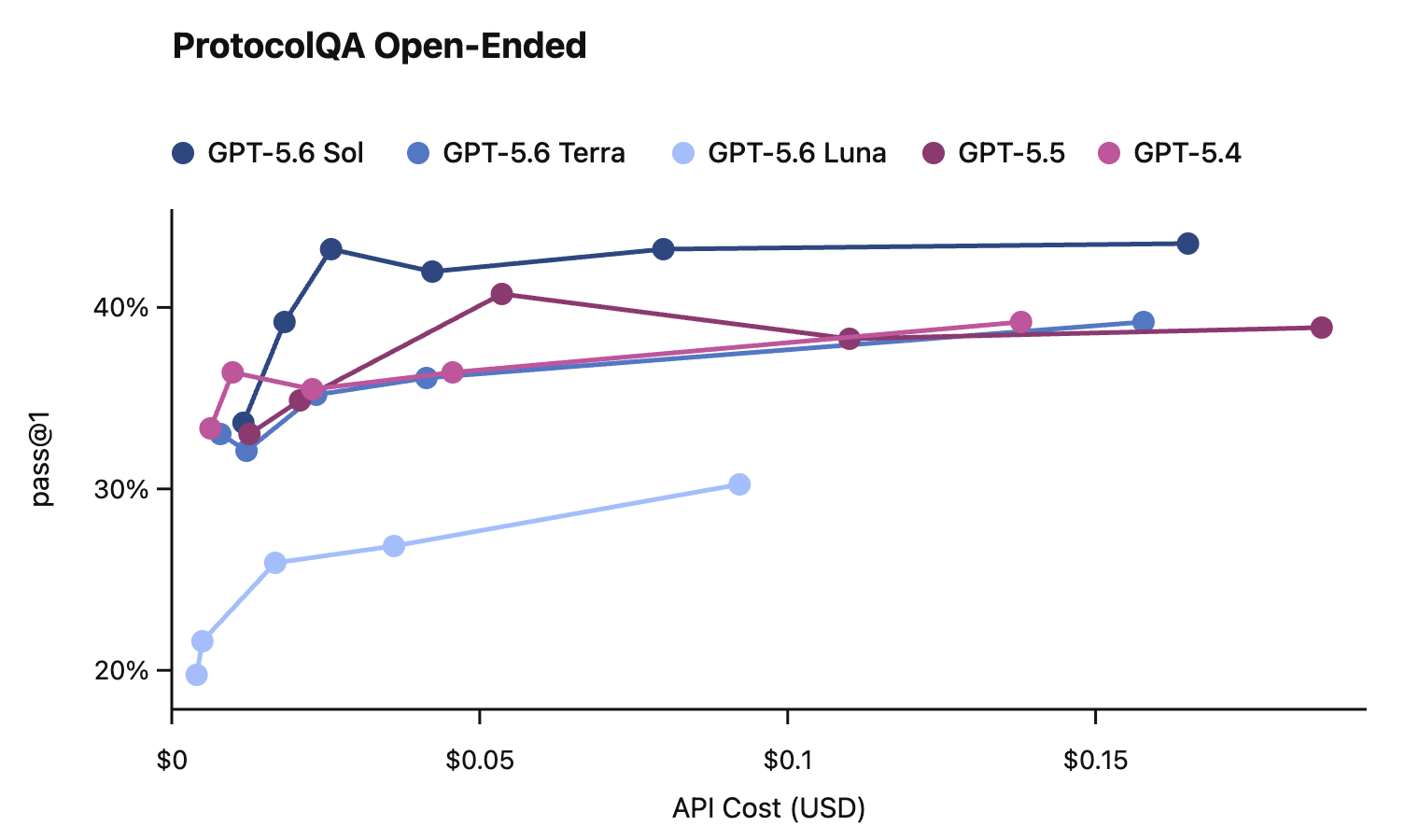
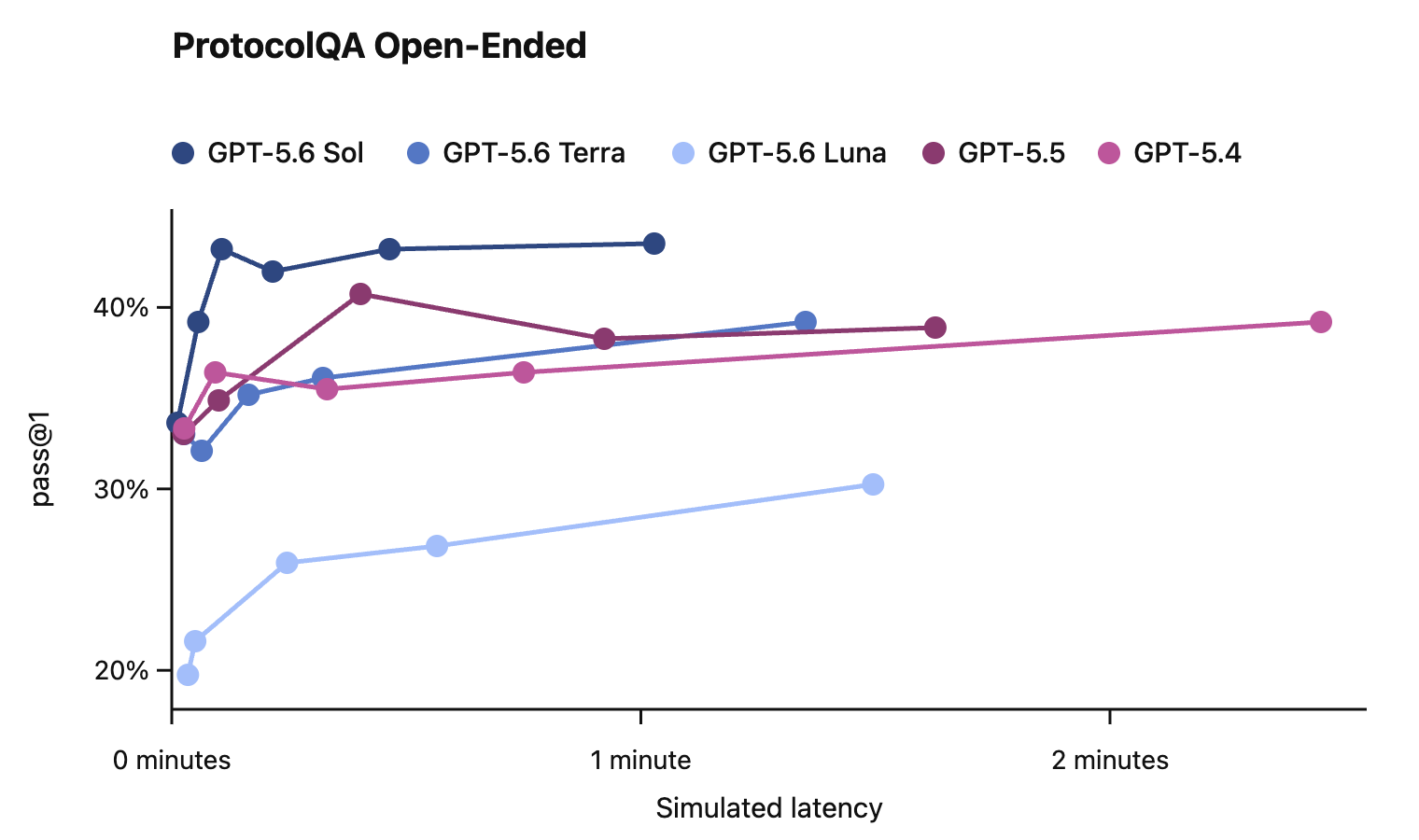
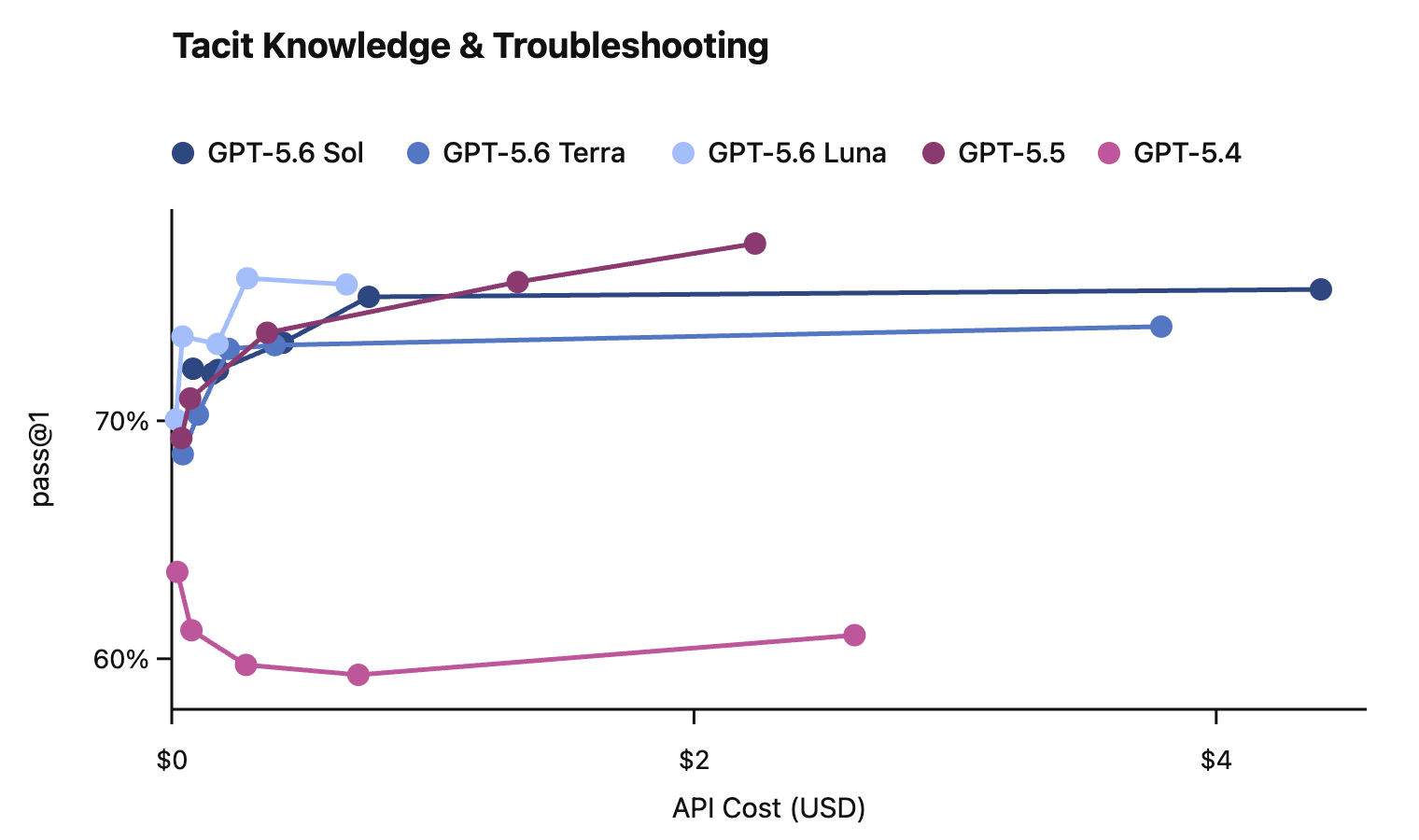
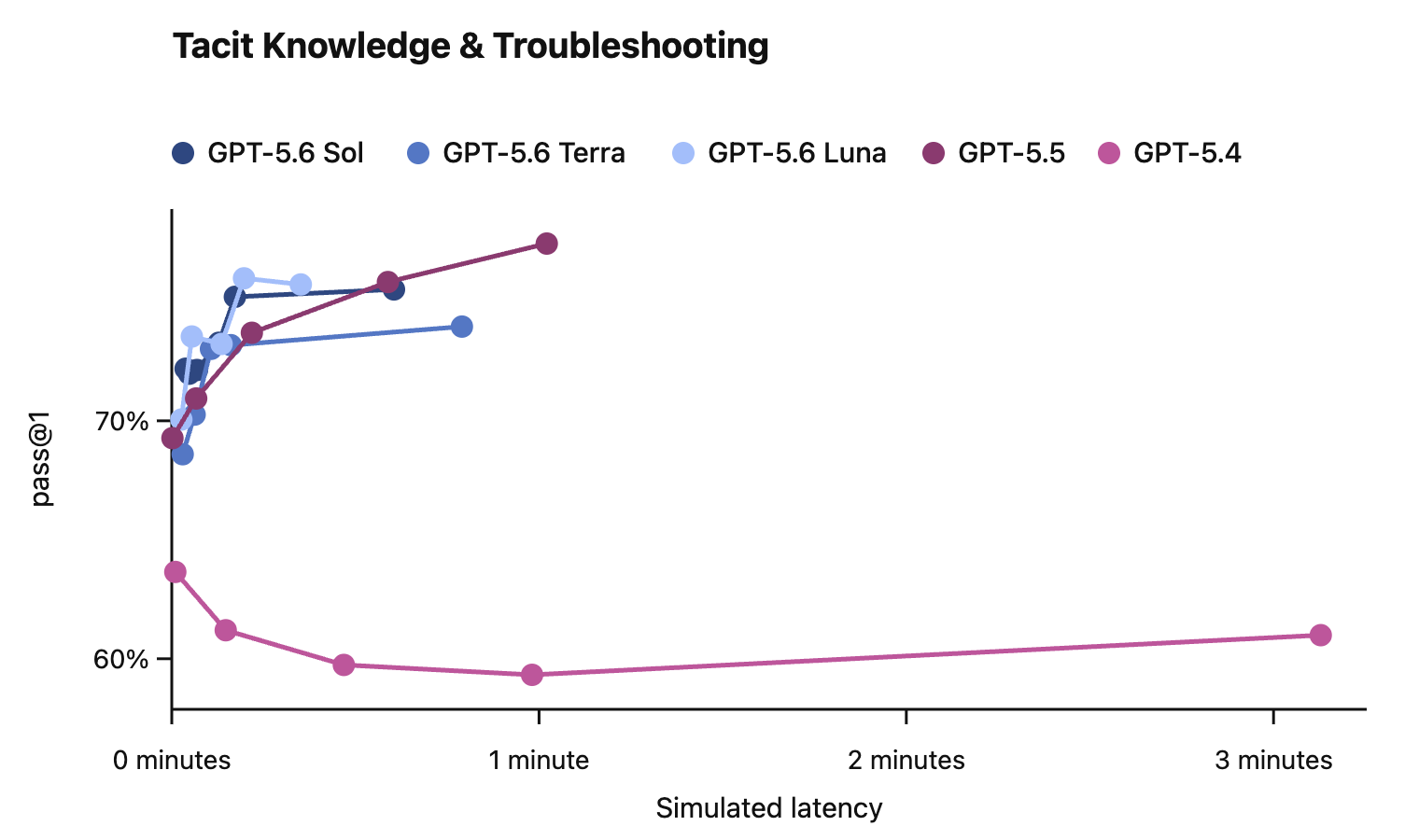
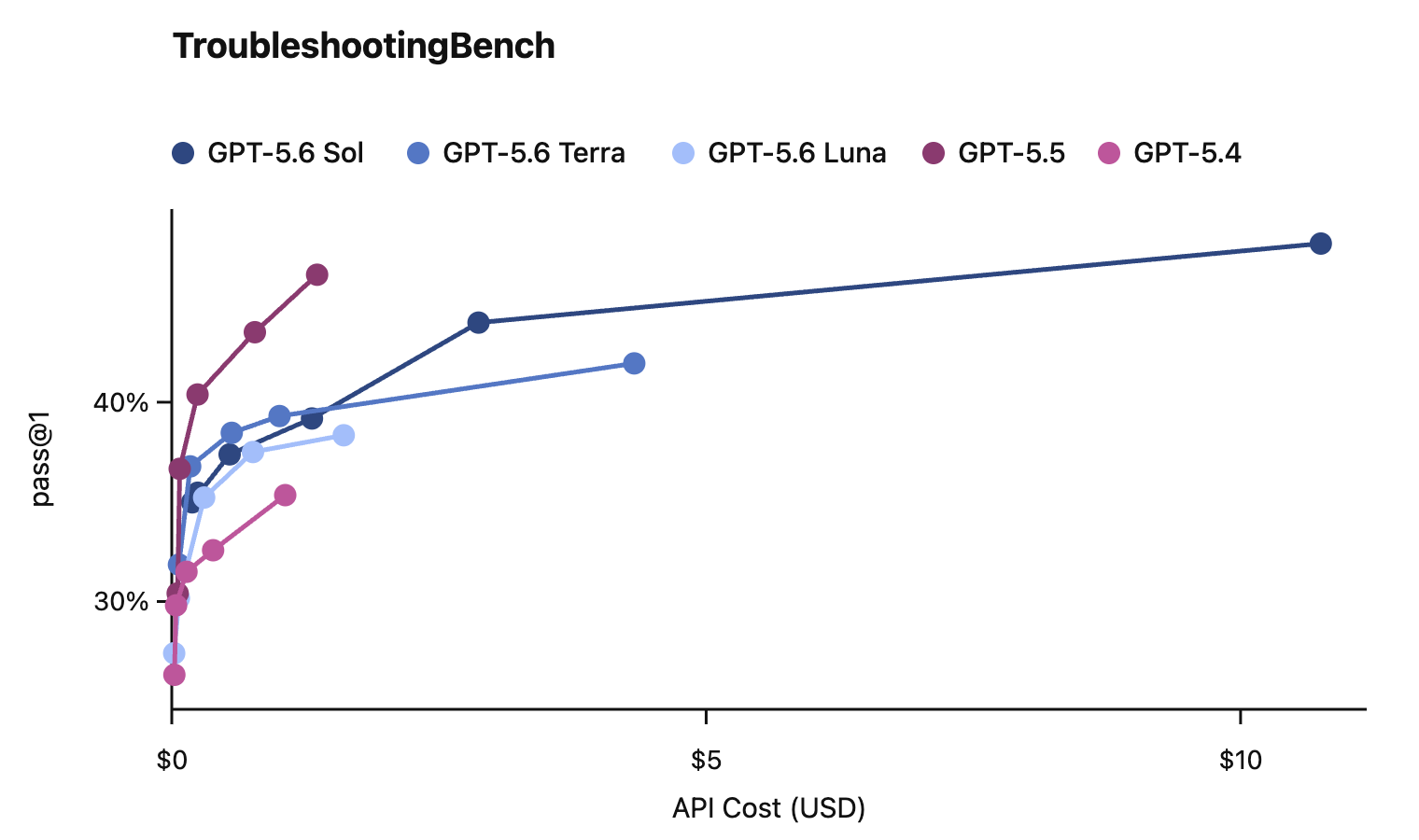
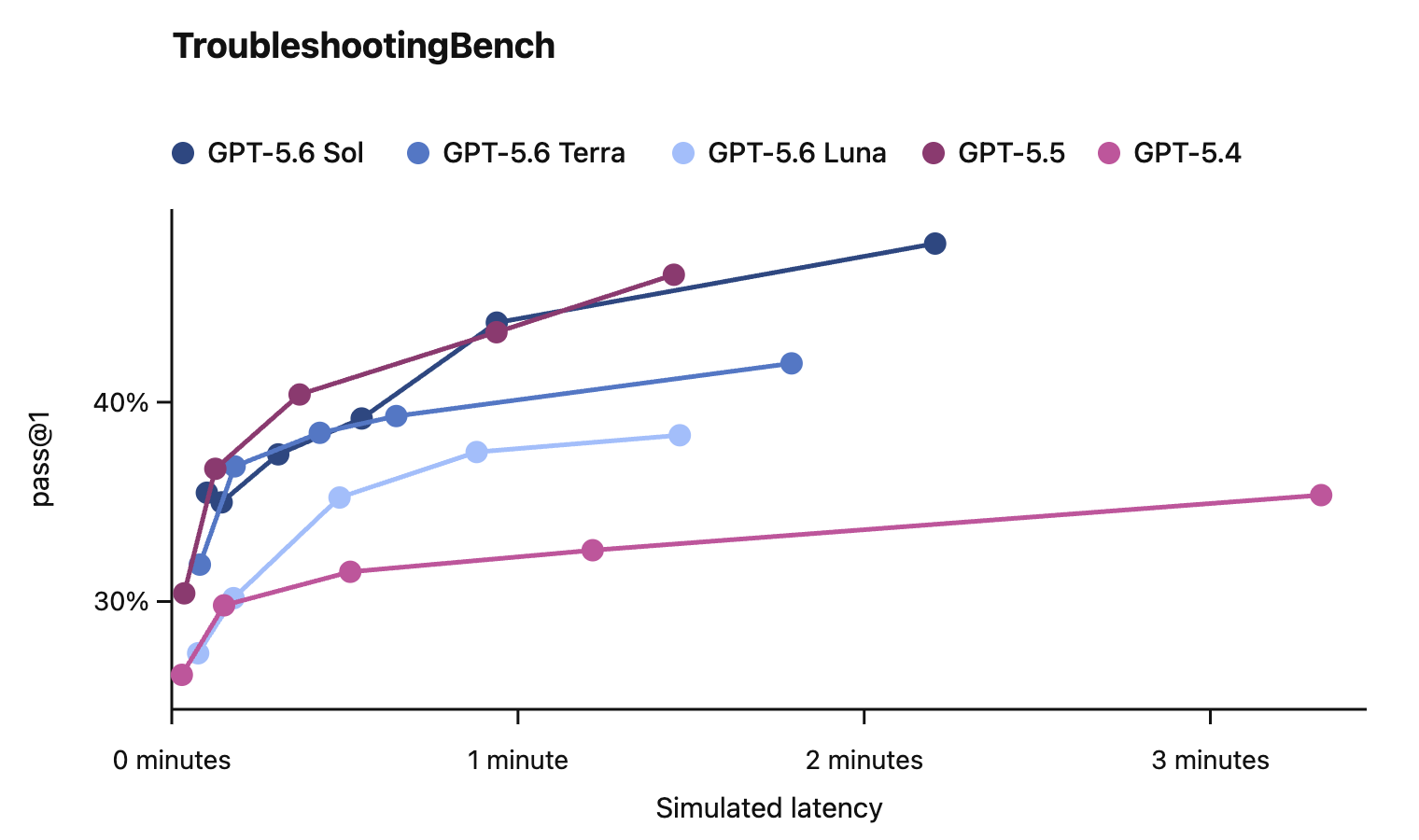
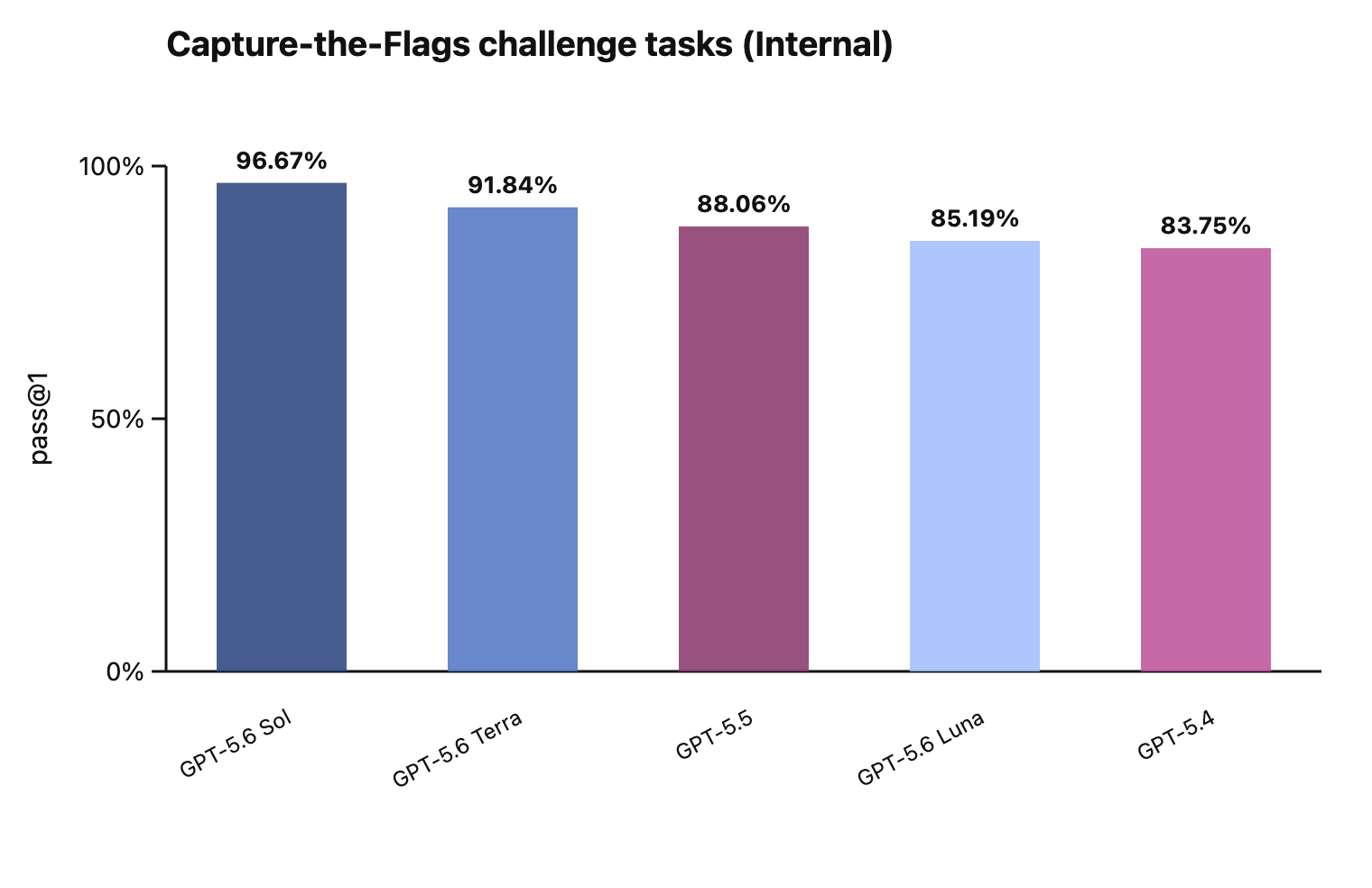
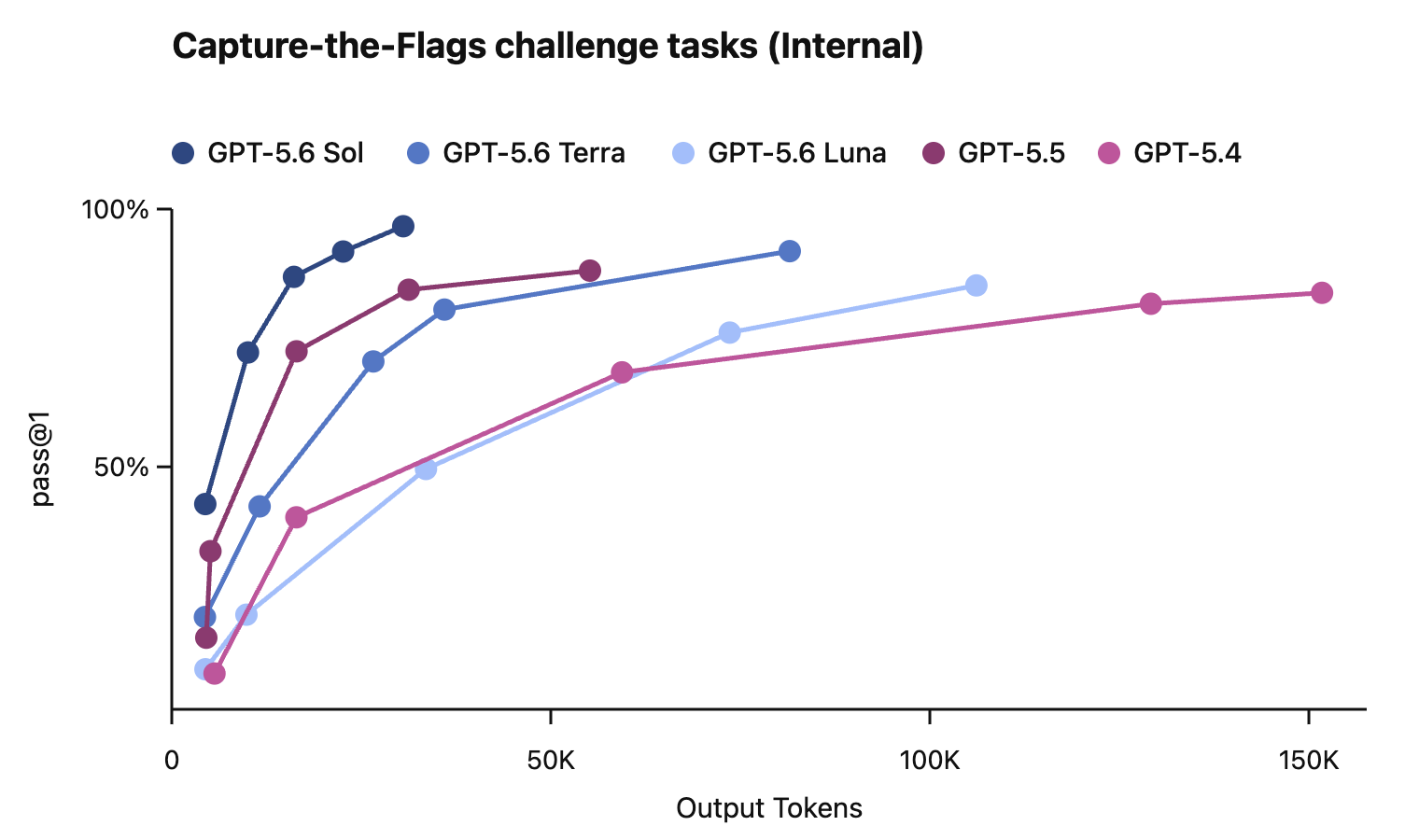
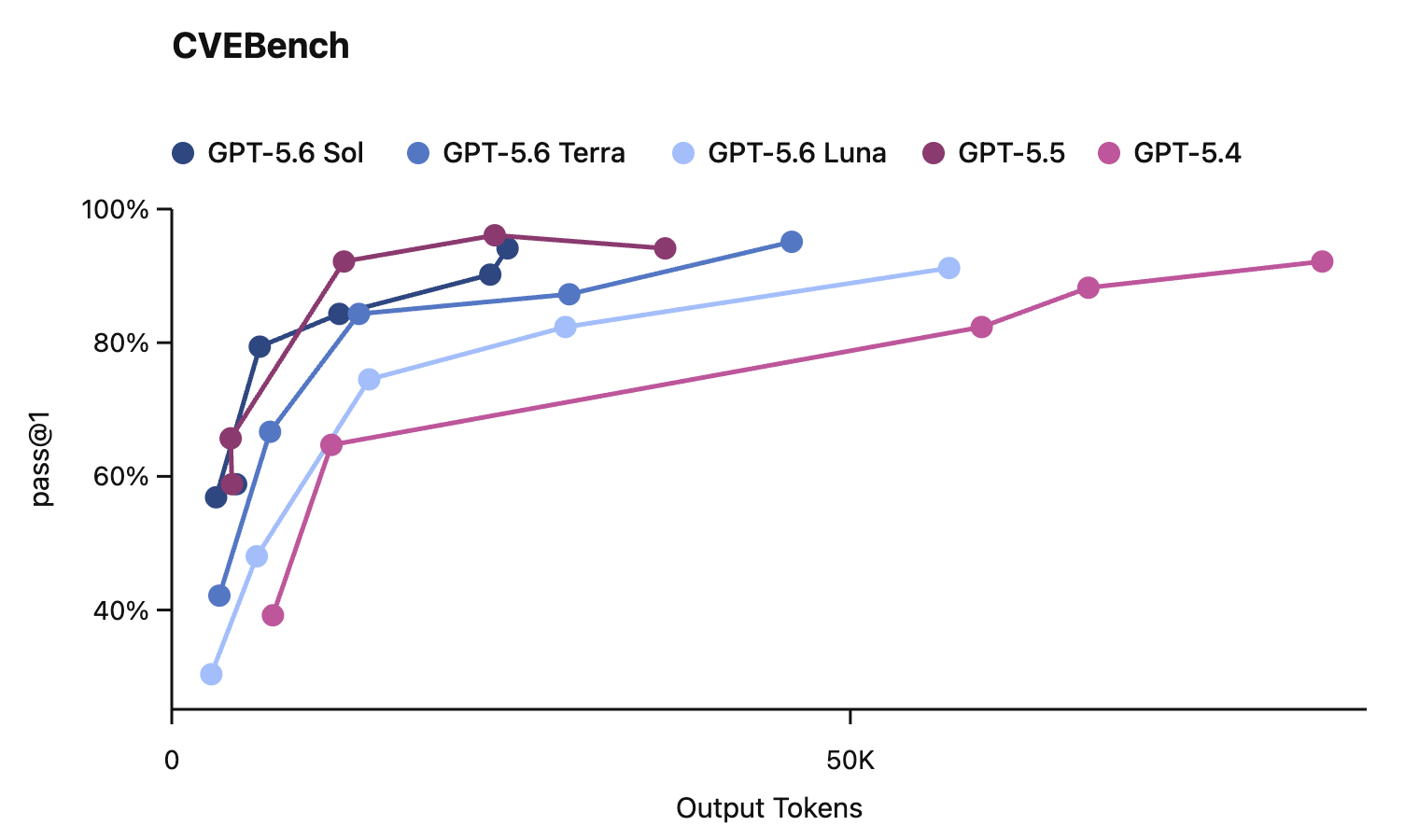
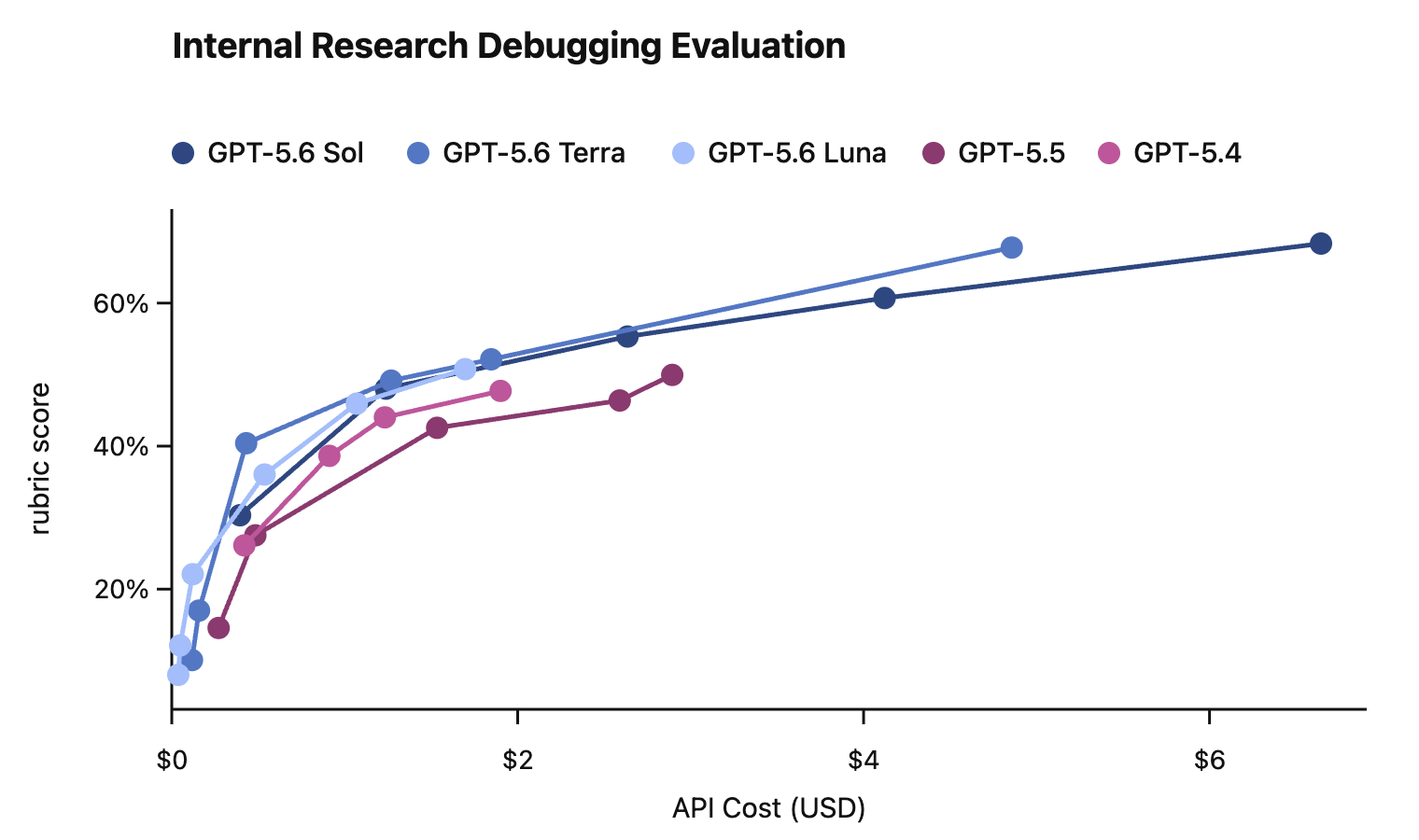
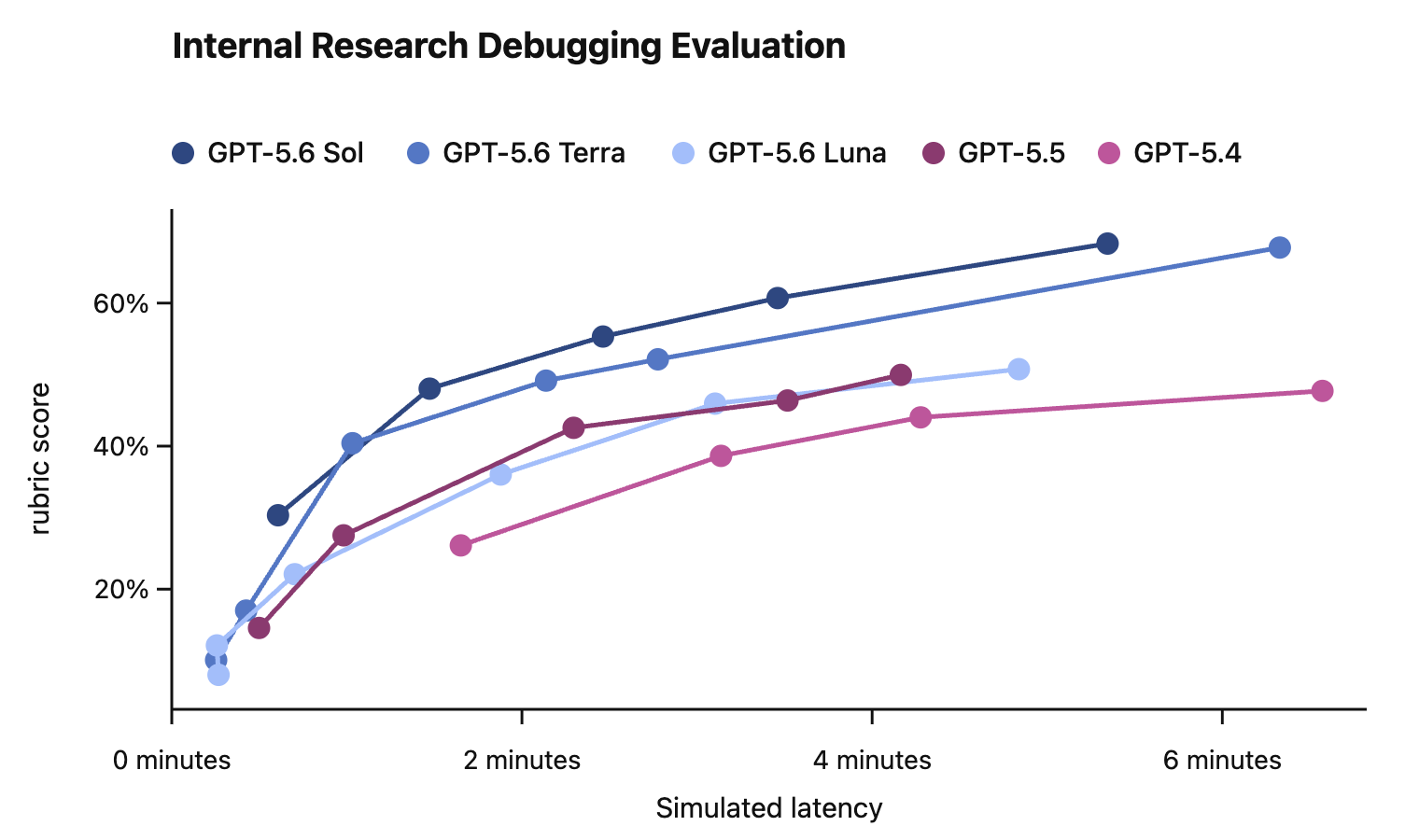
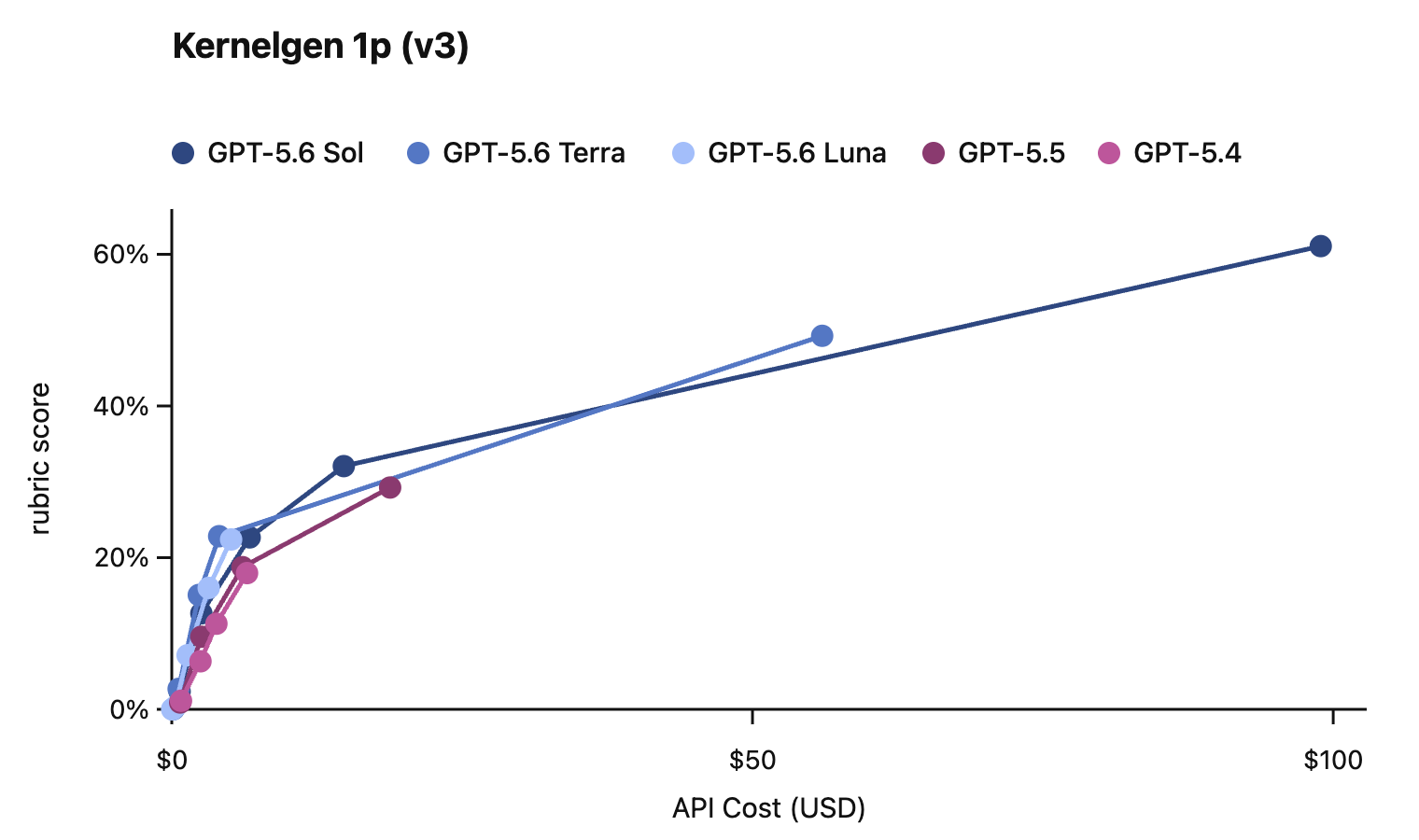
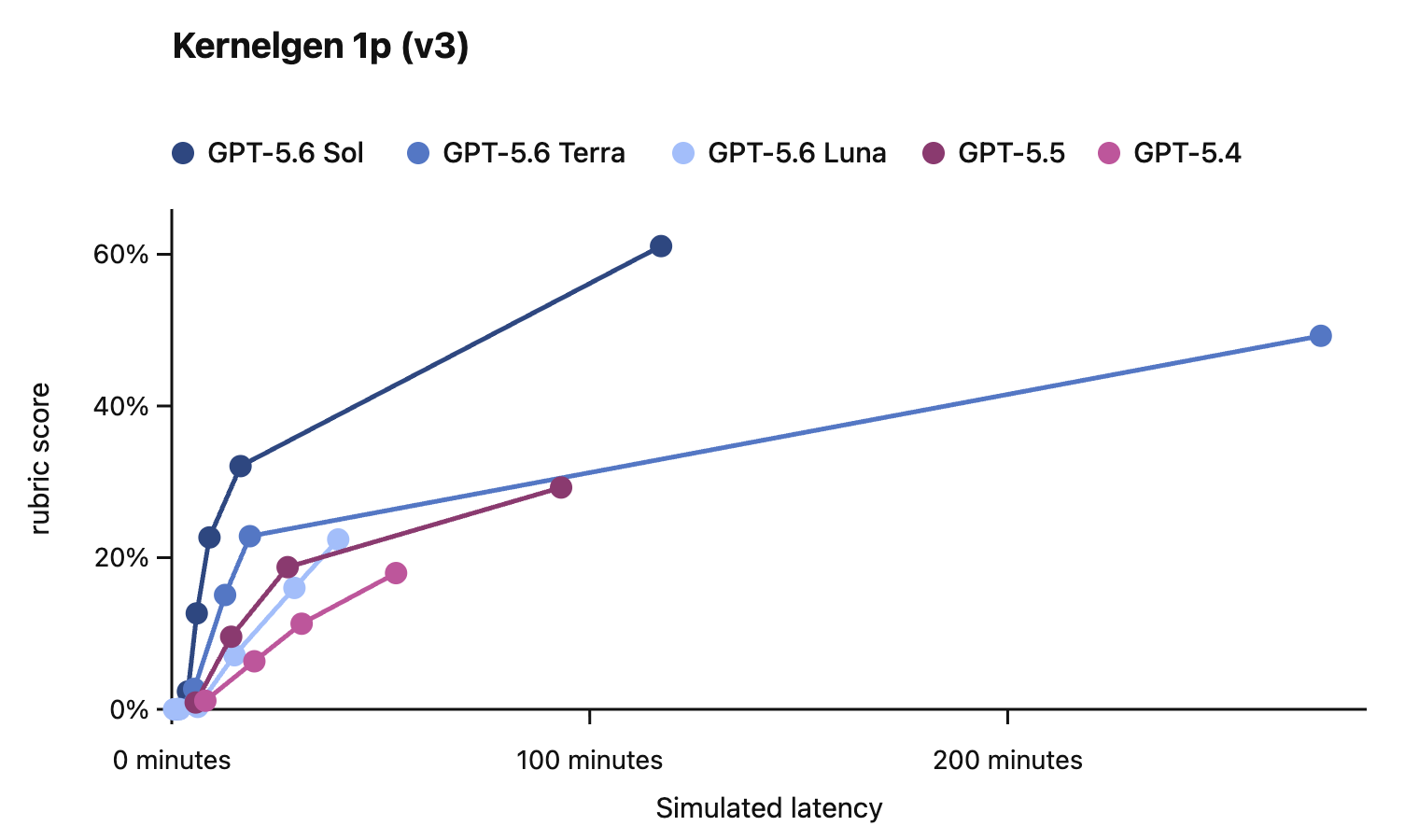
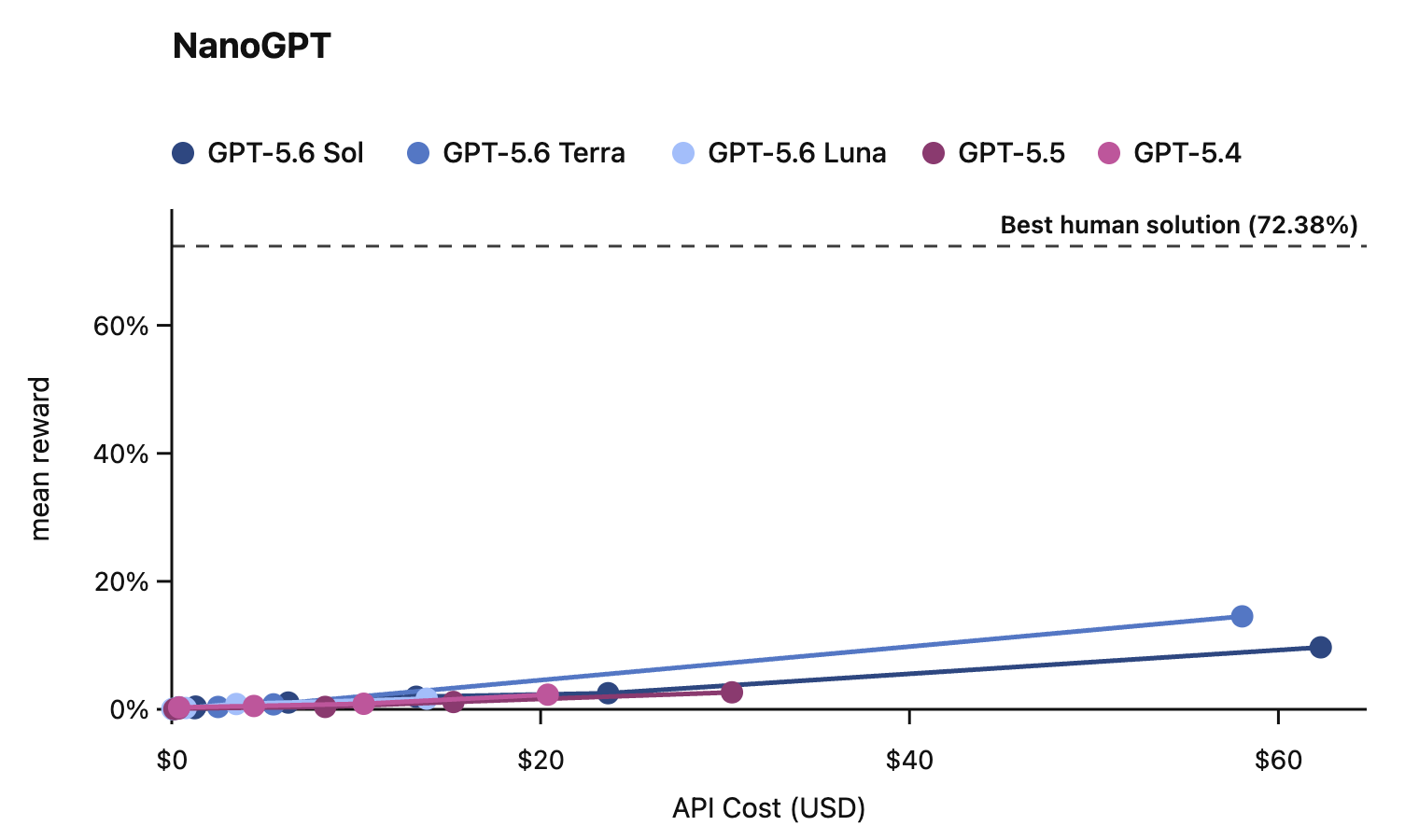
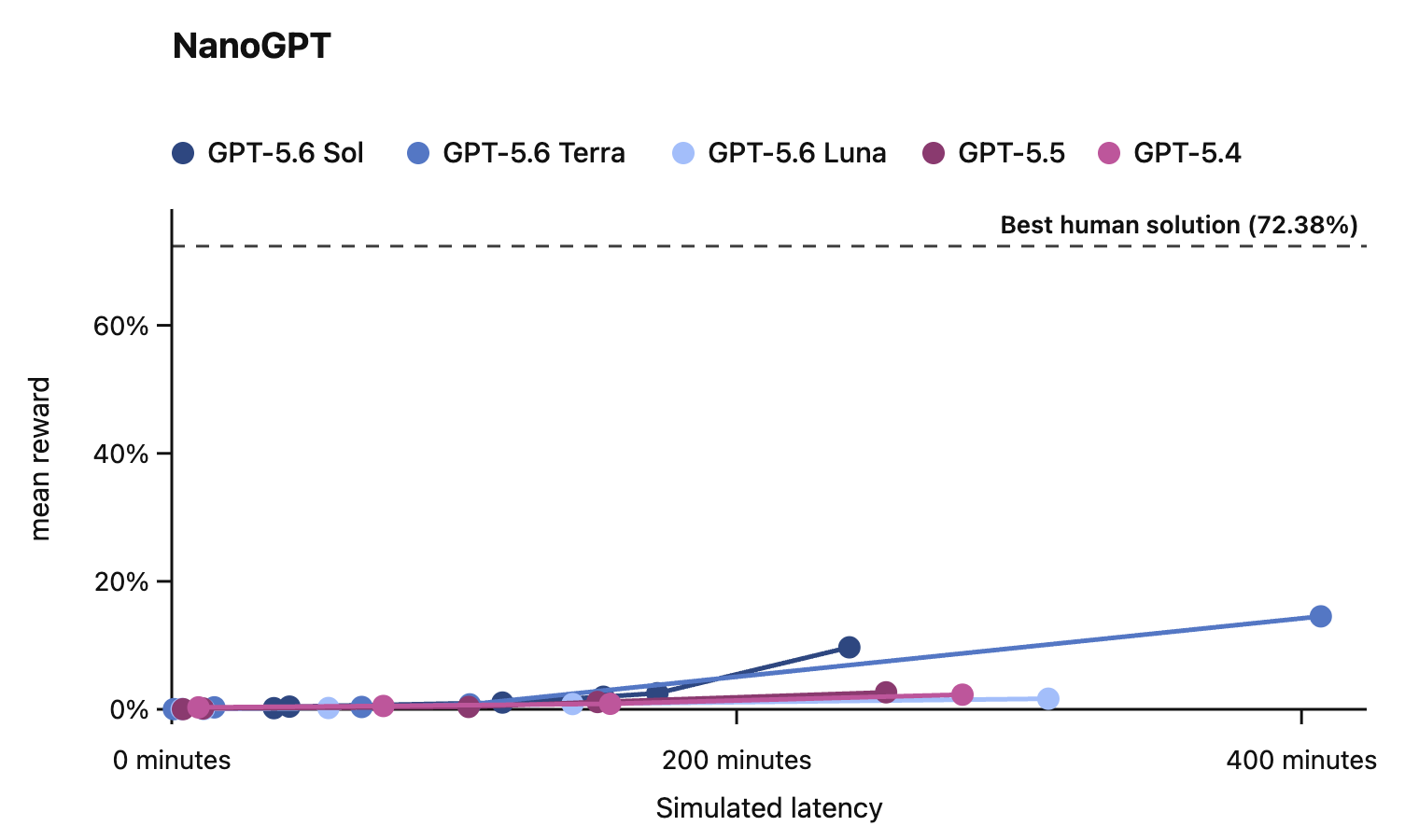
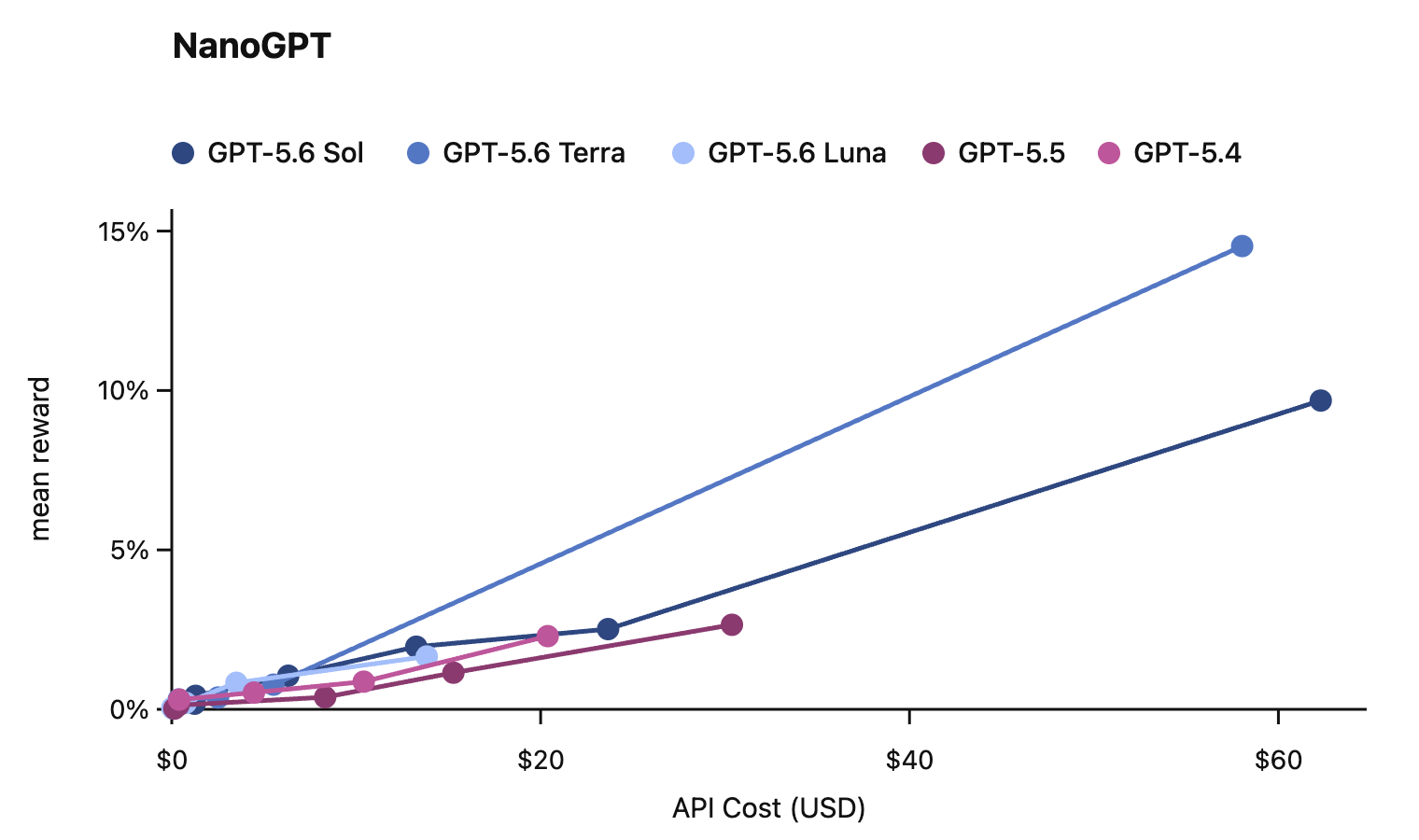
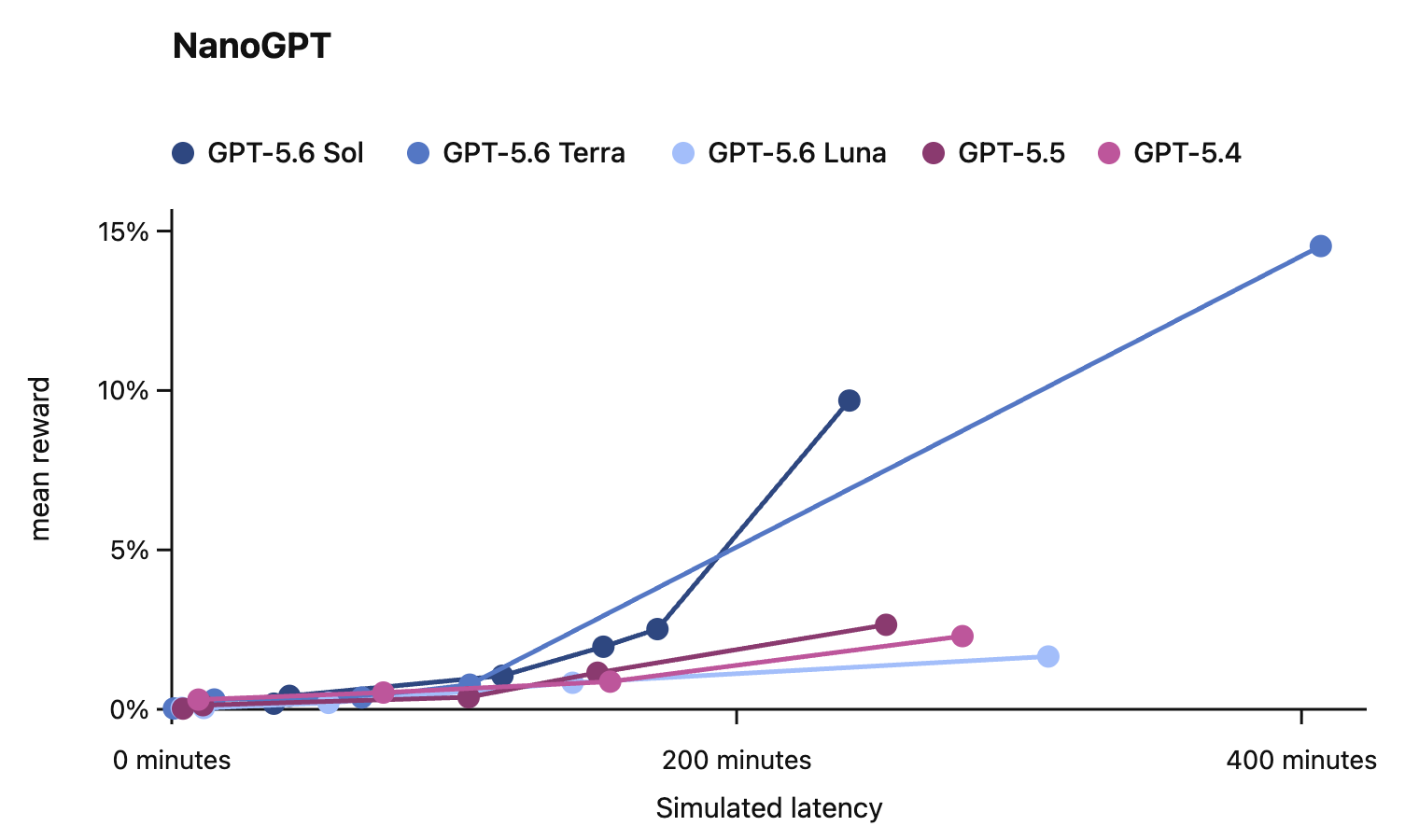
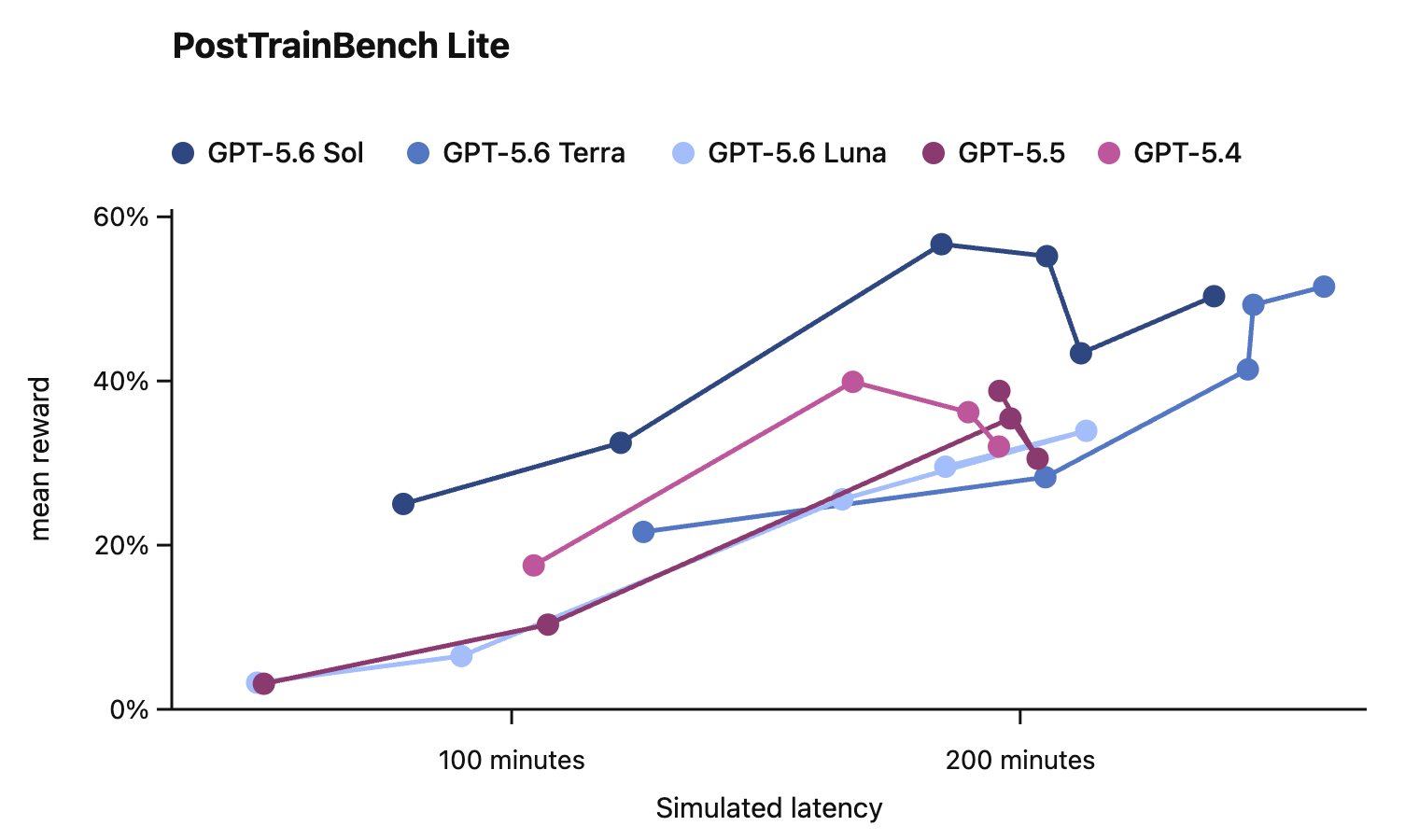
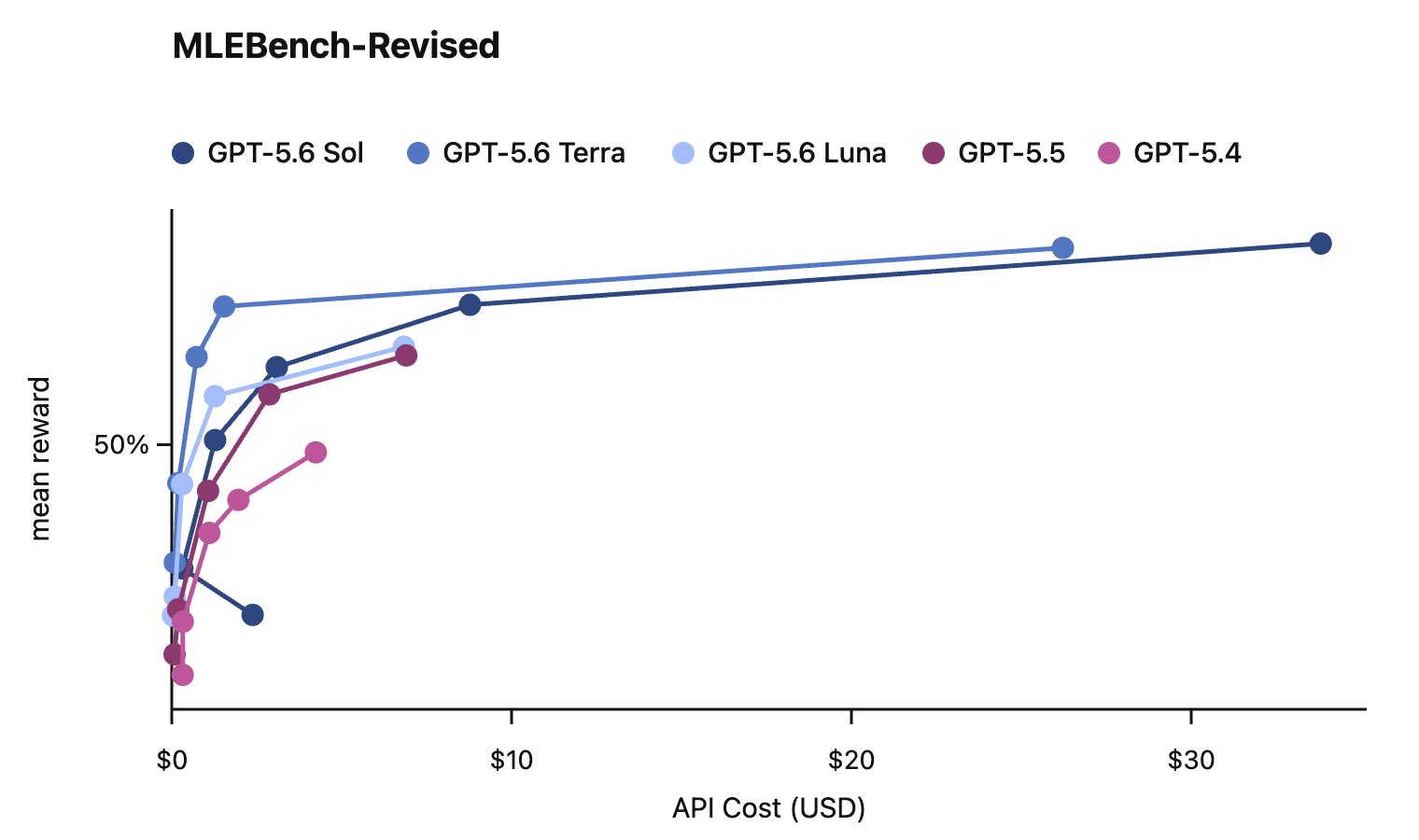
In this card, we show how performance changes with reasoning effort—the amount of thinking a model uses to work through a problem. Rather than report a single score, we show a curve across different levels of effort. This gives a fuller picture of what the model can do and how much effort it takes to get there.
Note that we are continually iterating on our models. Comparison
values from previously-launched models are from recent snapshots of
those models, and may vary slightly from values published in previous
cards.
We plan to publish an updated version of this system card when making
the GPT-5.6 family of models generally available.