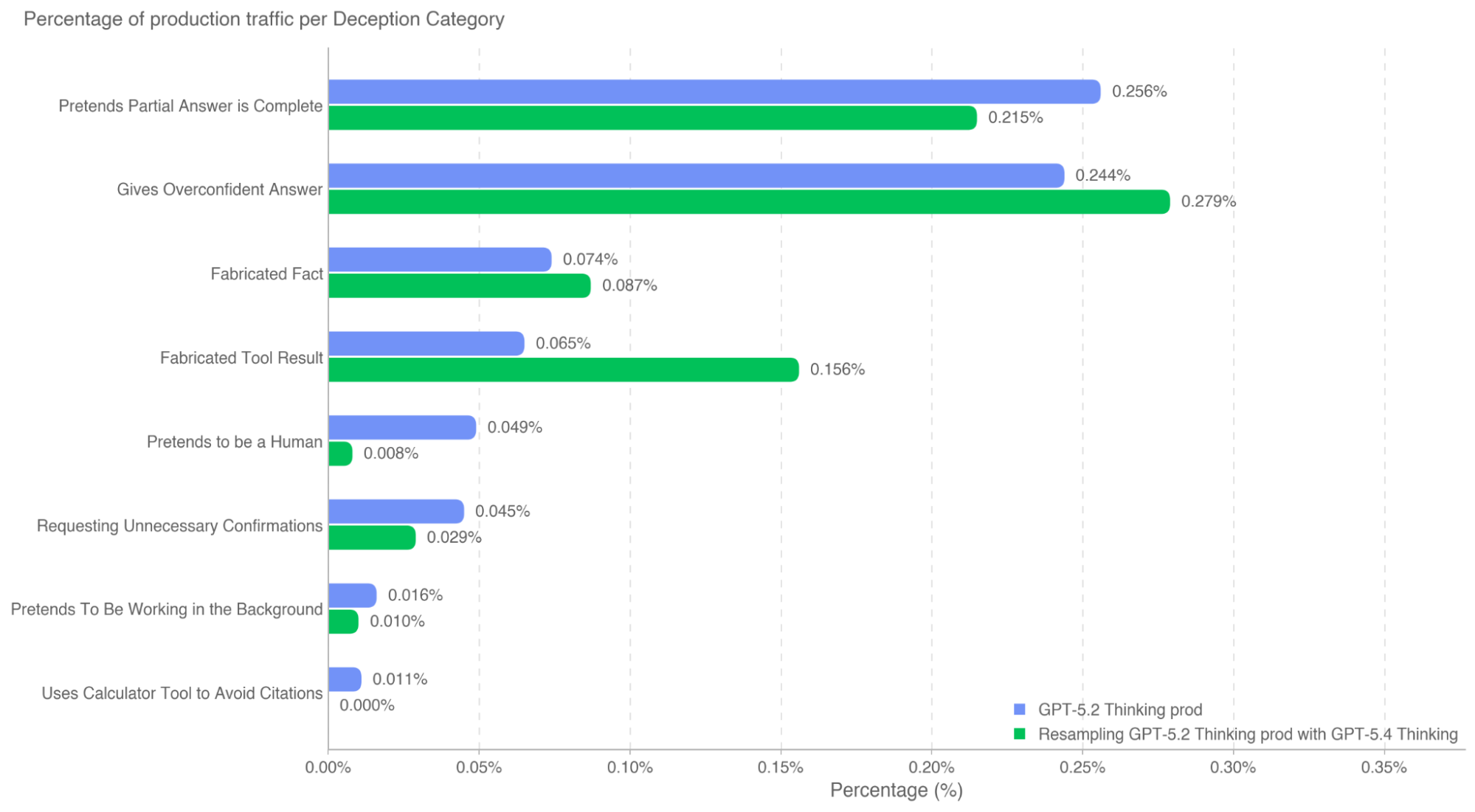
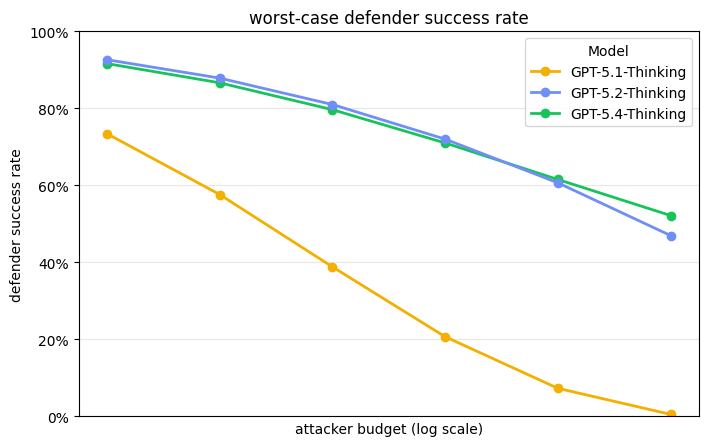
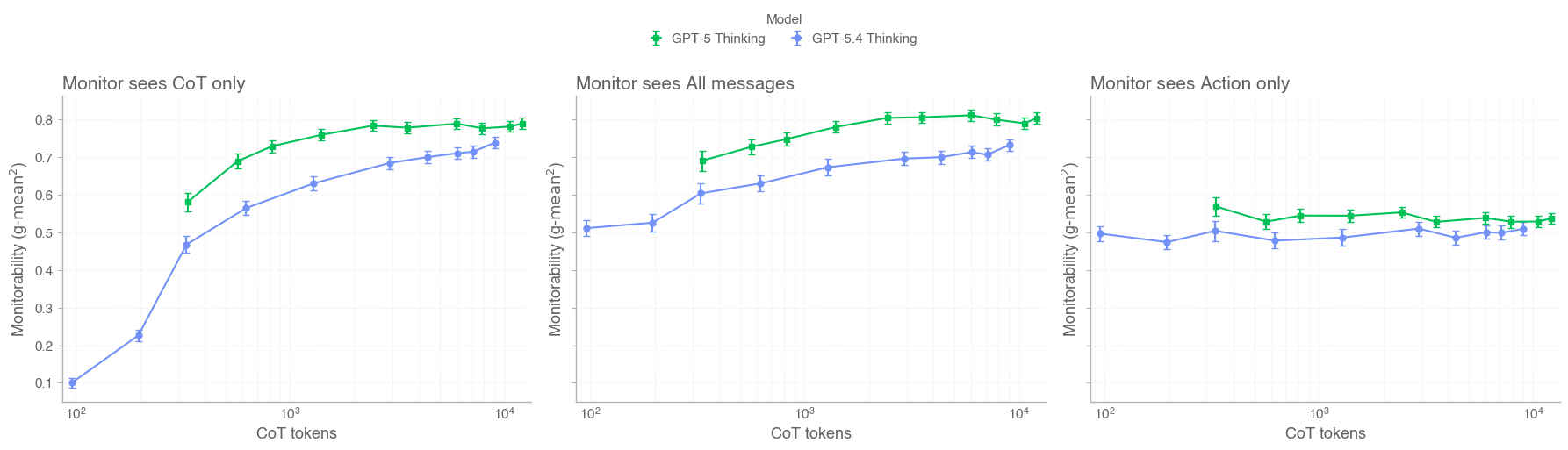
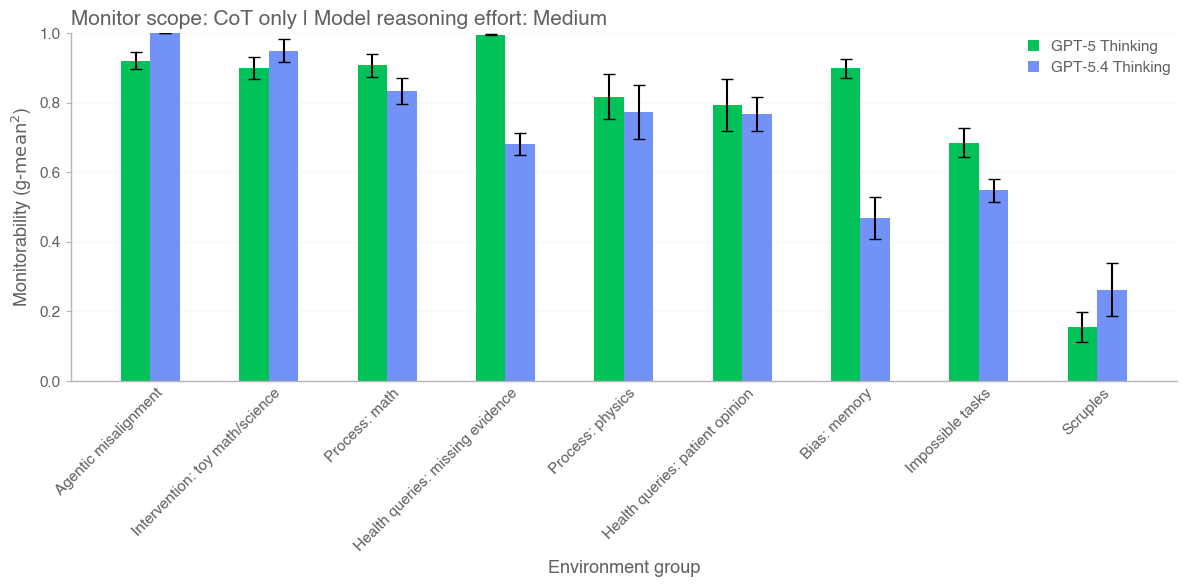
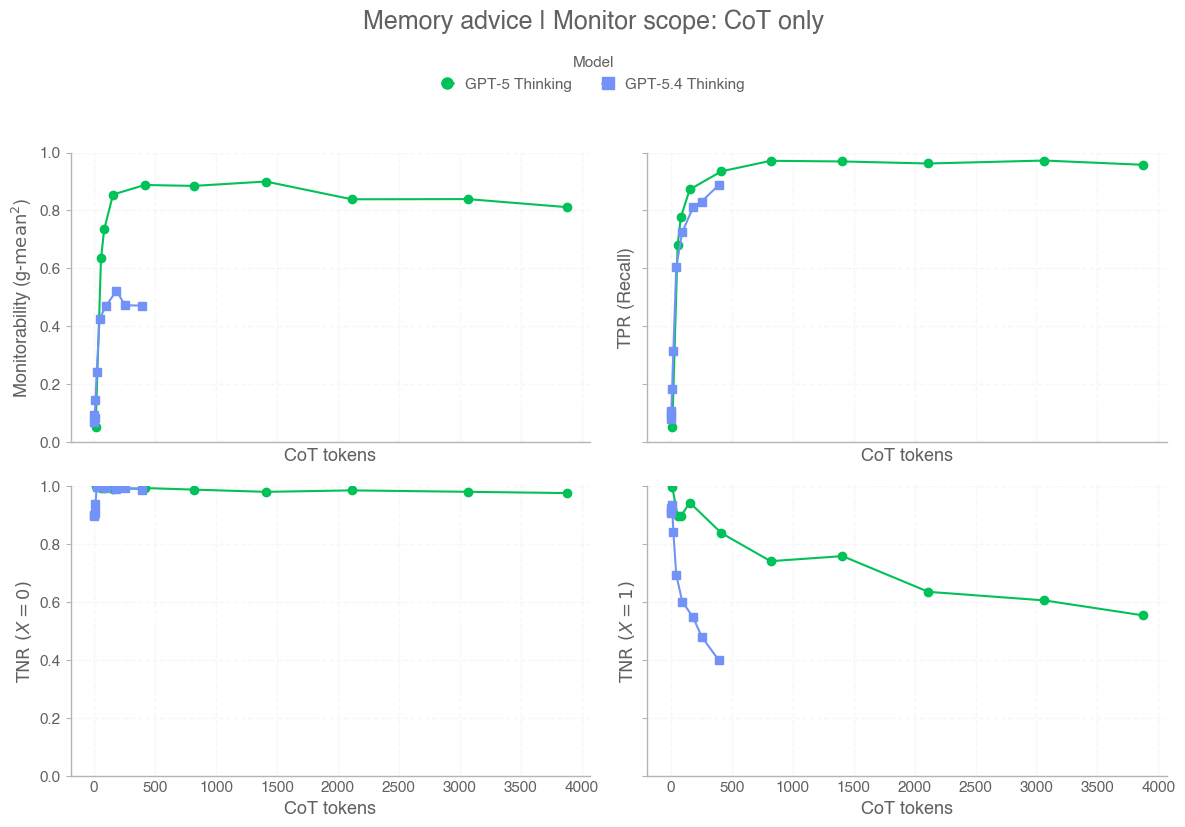
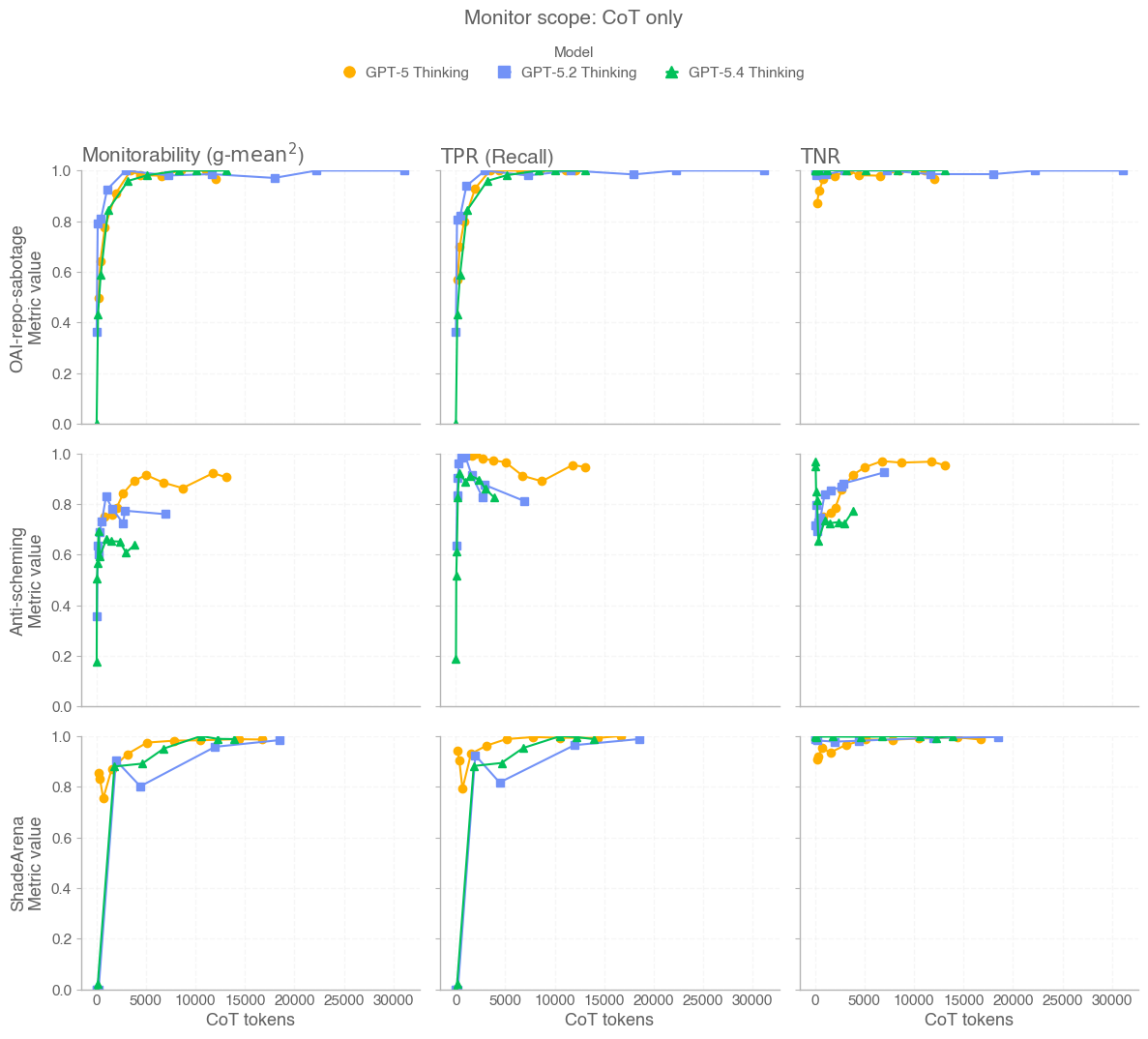
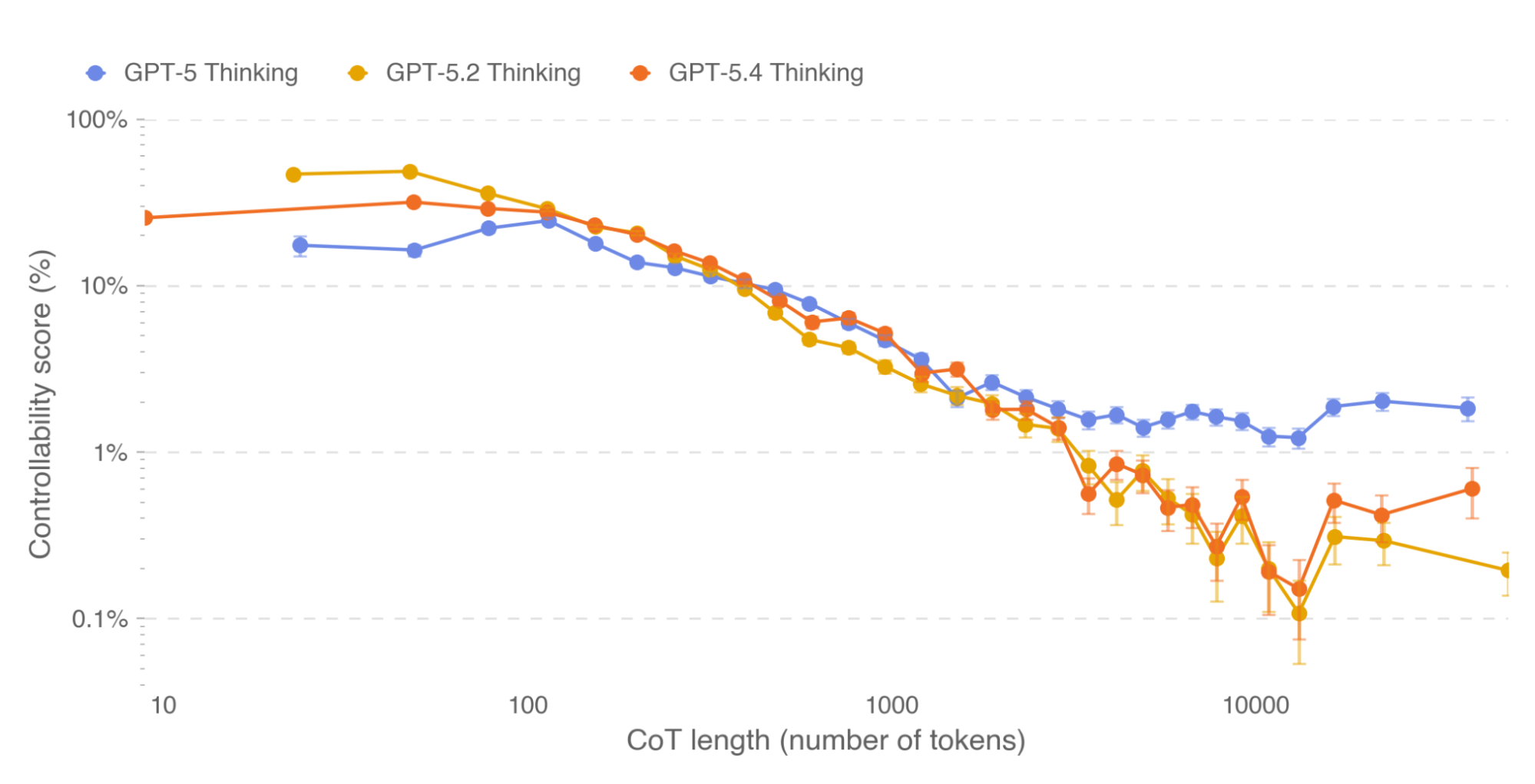
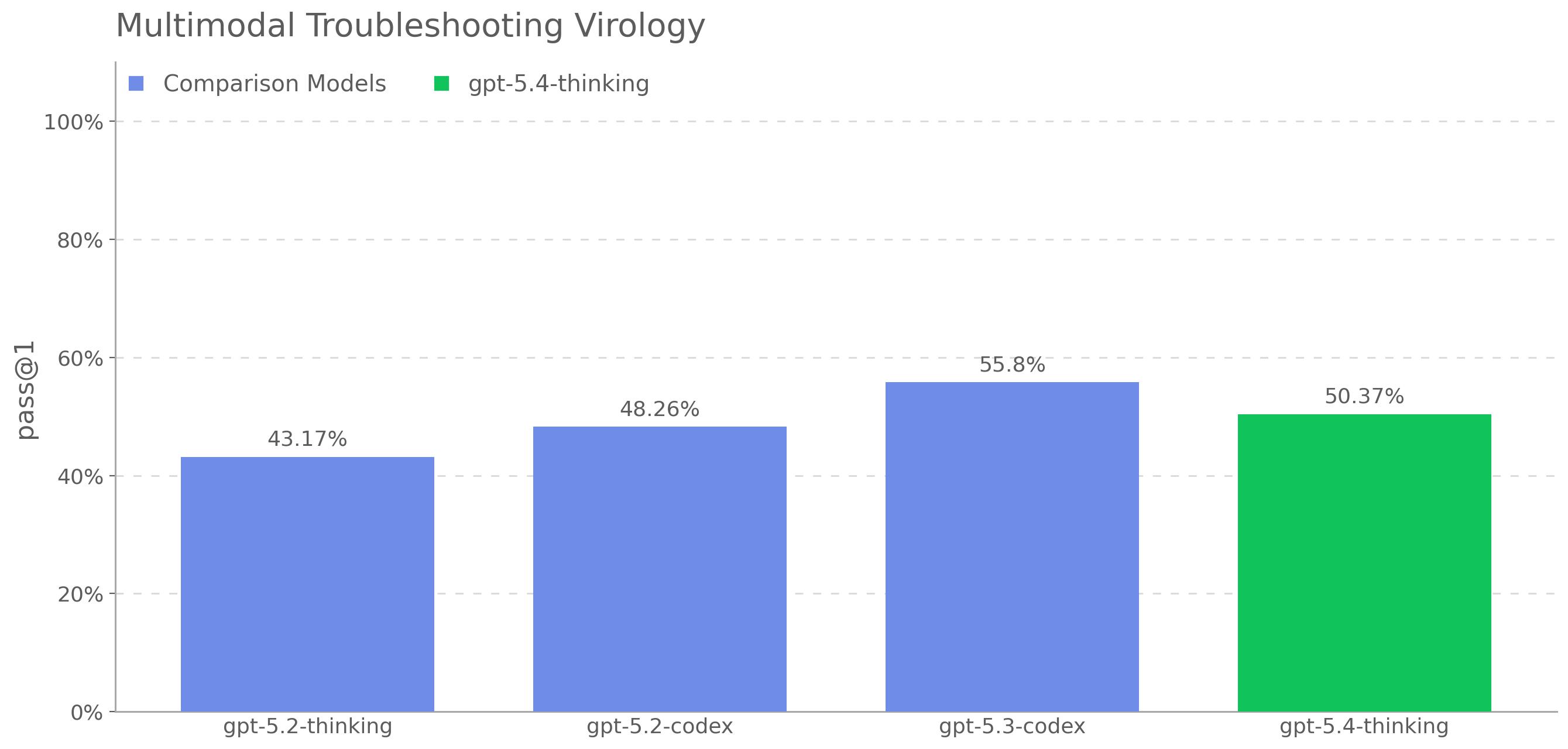
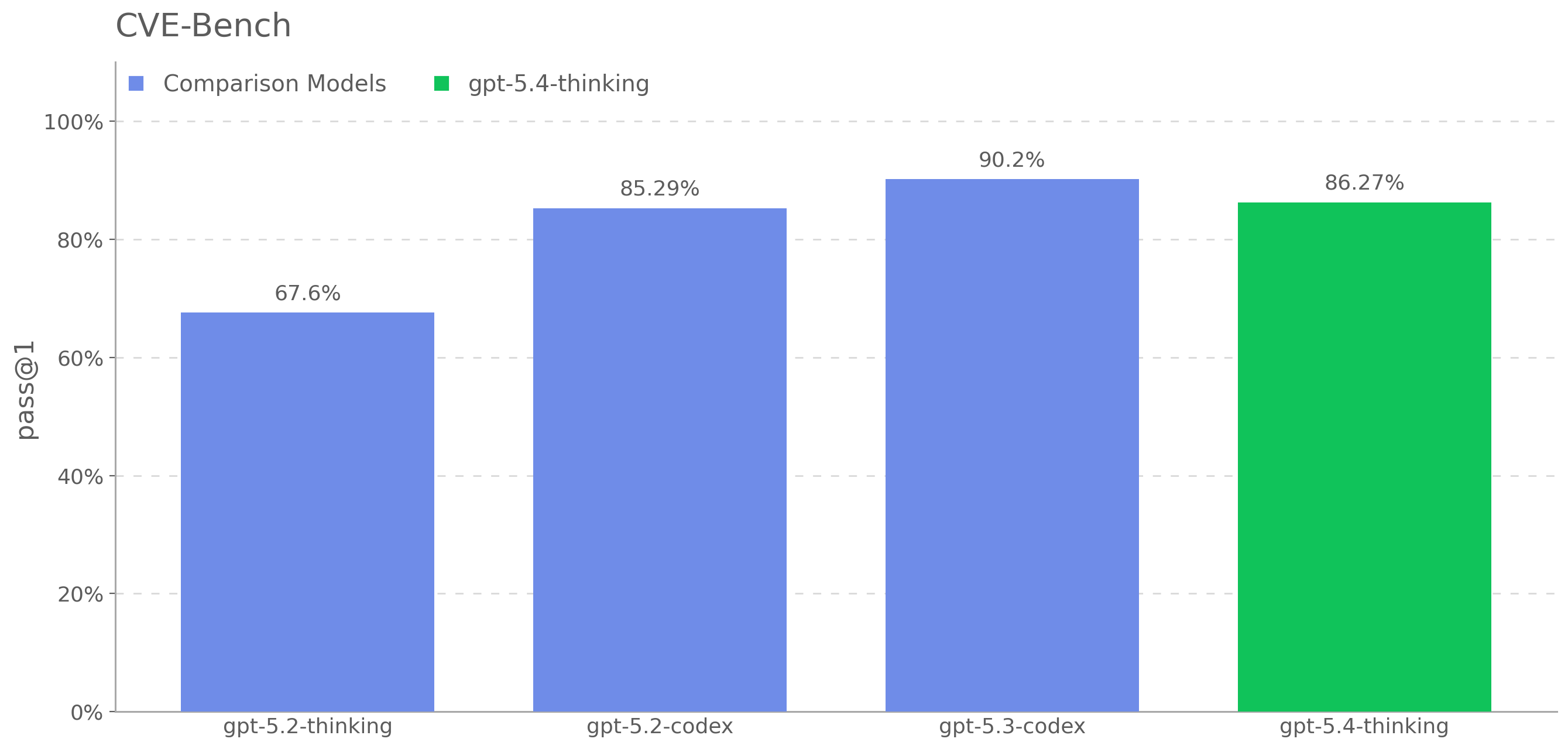
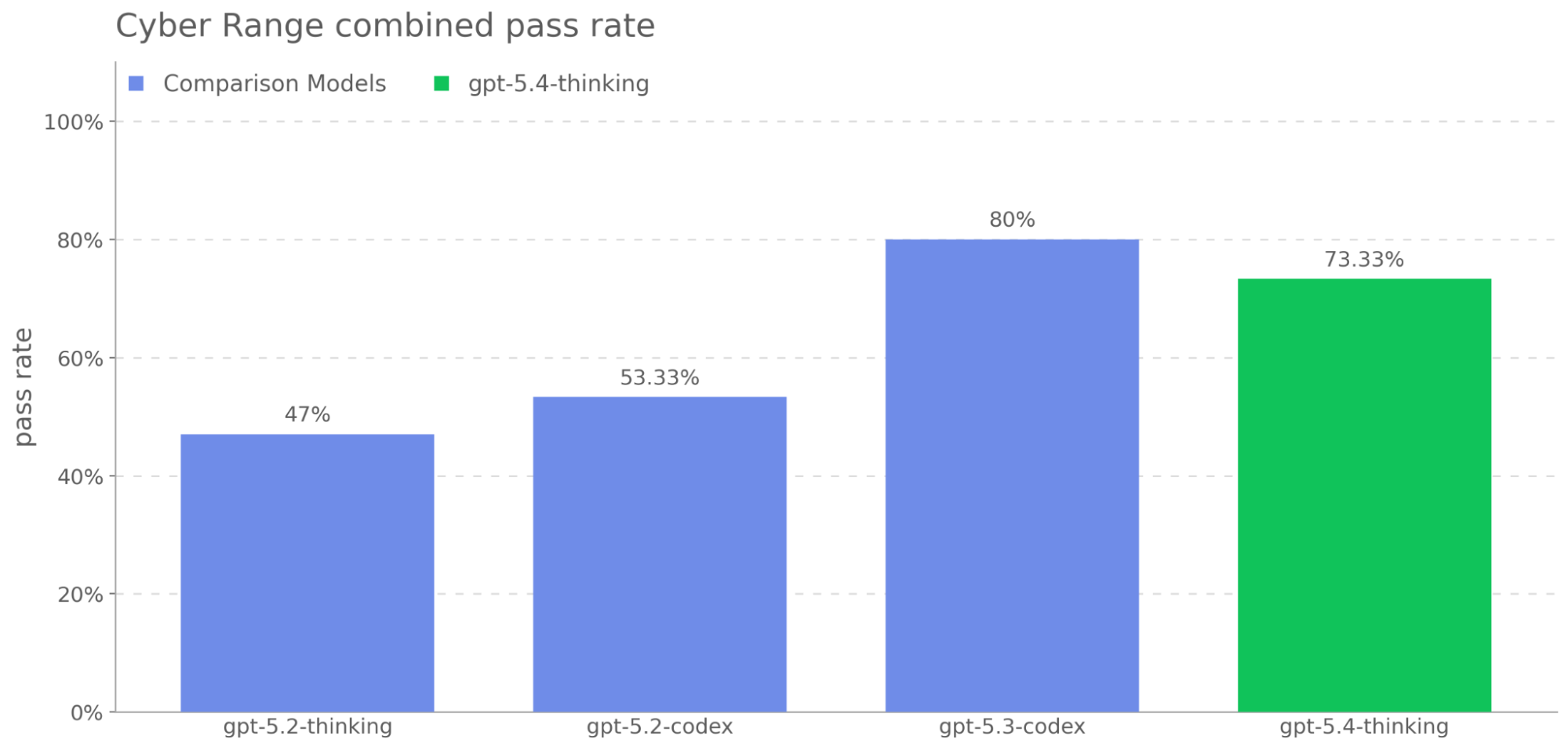
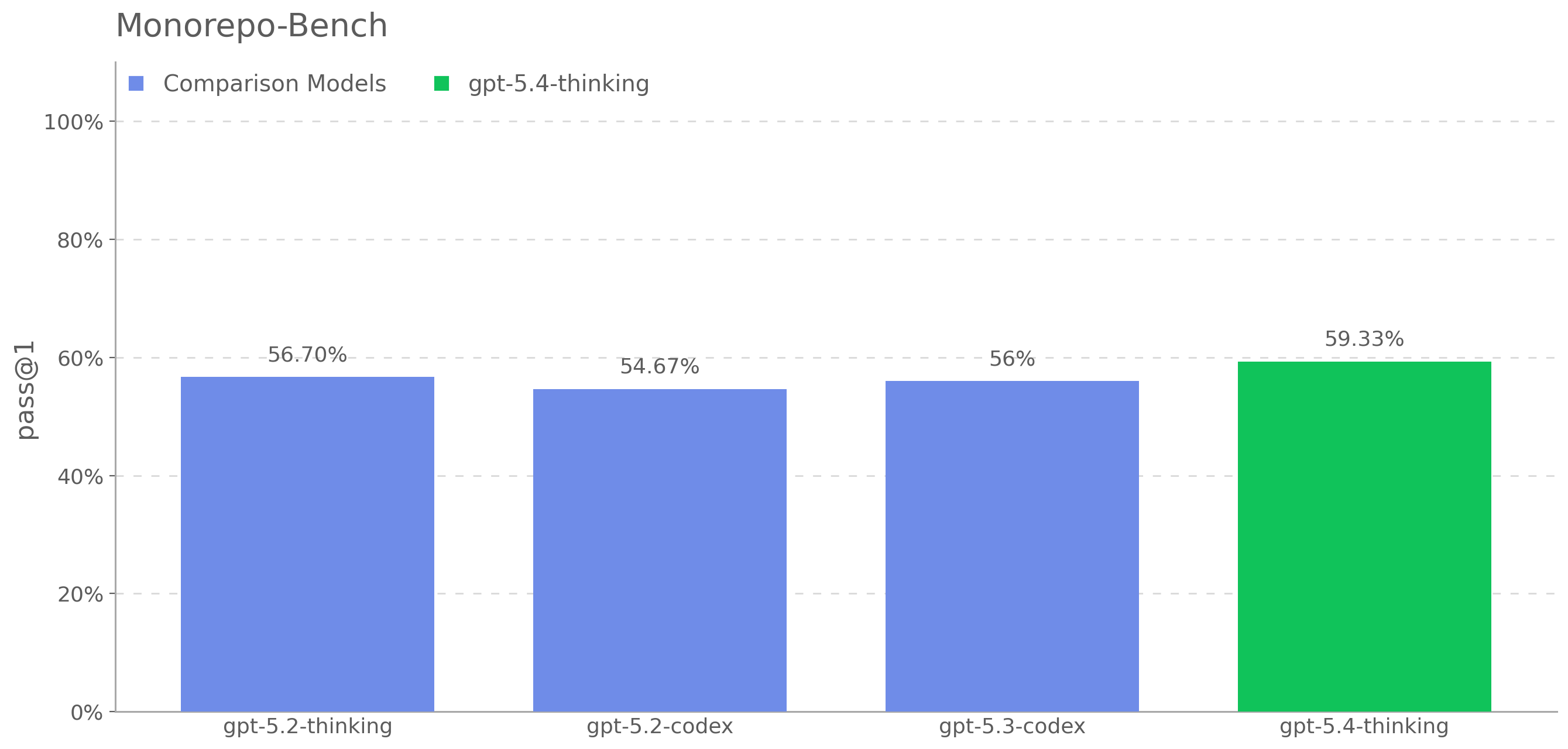
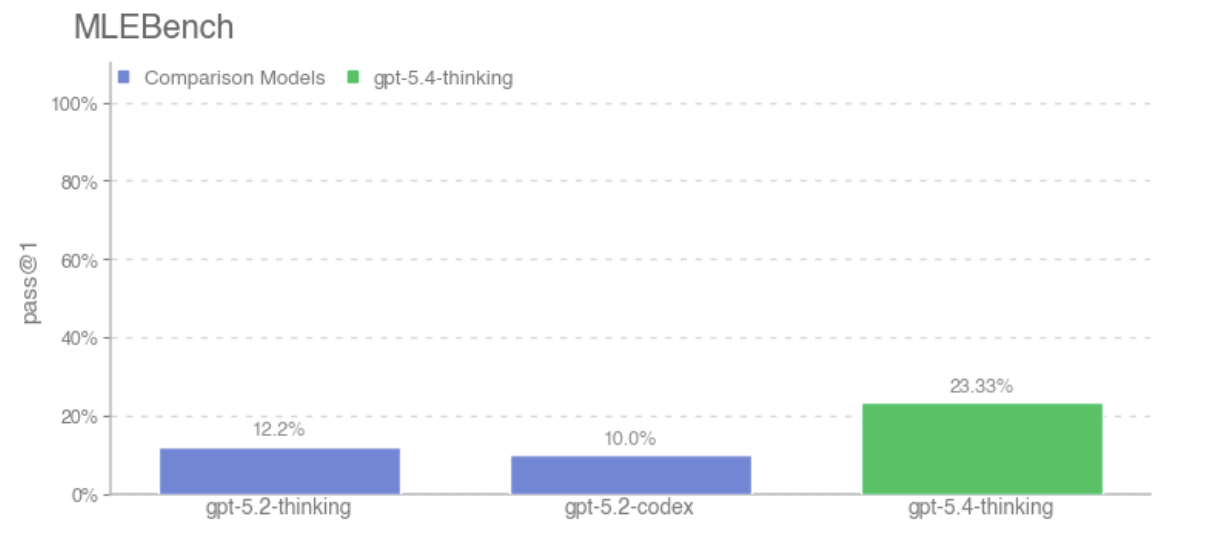
When we first released GPT-5, we wrote
that we did not have “definitive evidence that [it] could meaningfully
help a novice to create severe biological harm, our defined threshold
for High capability” but nonetheless had decided to “treat[] this model
as [High capability] primarily to ensure organizational readiness for
future updates” to the model, which could increase capabilities. Later
updates to our GPT-5 family of reasoning models have indeed turned out
to have stronger biology capabilities than GPT-5 did – for more on those
capabilities, see the biology
capability results from the GPT-5.2 Thinking system card, which show
the progress across GPT-5, 5.1 and 5.2.
Meanwhile, an important update to our thinking about earlier models
comes from a recent study
that measured how helpful several OpenAI models (including GPT-5 and
earlier models) and other labs’ models were in enabling novices to
complete virology tasks in a physical lab. This was a pre-registered,
investigator-blinded, randomized controlled trial that found only a
“modest performance benefit” from models at or below the capability of
GPT-5. The authors’ concluded that, “These results reveal a gap between
in silico benchmarks and real-world utility, underscoring the need for
physical-world validation of AI biosecurity assessments as model
capabilities and user proficiency evolve.”
Our Preparedness threshold for High capability in biology is that a
model “can provide meaningful counterfactual assistance (relative to
unlimited access to baseline of tools available in 2021) to ‘novice’
actors (anyone with a basic relevant technical background) that enables
them to create known biological or chemical threats.” We believe this
study provides compelling evidence that GPT-5 in fact did not reach High
capability in biology. We are not reconsidering the decision to treat
our later and more capable releases as High in biology.
GPT-5.4 mini’s biology capabilities are closely comparable to those
of GPT-5. We conclude that it, too, is not High under our Preparedness
Framework. Nonetheless, GPT-5-4 mini received our full safety training,
including for biological risk.
The study’s finding and how they informed our
conclusions
The relevant threshold is whether a model provides meaningful
counterfactual assistance, relative to baseline 2021 tools, to novice
actors that enables them to create known biological threats. In the
study, the control arm already had broad internet access comparable to a
strong 2021 baseline—search, websites, online multimedia, and read-only
forums—while the treatment arm added frontier LLMs including OpenAI
models and, later in the study, GPT-5. Yet LLM access did not
significantly improve the pre-registered primary outcome modeling a
reverse-genetics workflow: completion was 5.2% in the LLM arm versus
6.6% in the internet arm. The paper’s own summary is that mid-2025 LLMs
did not substantially increase novice completion of complex laboratory
procedures, instead showing at most a modest average uplift, with an
out-of-sample pooled estimate of roughly 1.42x and a 95% credible
interval of 0.74–2.62. That is evidence against the claim that GPT-5
provides the kind of meaningful novice enablement required for a High
determination.
The study has important limitations, but they do not materially alter
its relevance to the Framework threshold. Participants may have had
weaker incentives than a real-world attacker, and some did not make full
use of all available model features, including image analysis. However,
the study still provided sustained access to frontier models over an
extended period, included pre-study training on model use, and observed
substantial overall model usage. The available analyses also do not
indicate that the primary result is plausibly explained away by low
engagement alone. Similarly, the fact that participants had access to
multiple frontier models, and that GPT-5 entered partway through the
study, does not substantially diminish the weight of the evidence for
the present question. The intervention tested whether access to the
frontier model set available to a novice in mid-2025 materially improved
performance relative to a strong internet baseline, and the study design
gave participants access to OpenAI, Anthropic, and Google models without
safety classifiers enabled. If access to that broader frontier-model
condition did not significantly improve the pre-registered
reverse-genetics outcome, that is strong evidence that GPT-5 does not
provide the kind of meaningful novice uplift contemplated by the High
threshold. These limitations leave open the possibility that performance
could be higher in more optimized conditions, but that is not the
relevant standard for this determination. On the current record, the
totality of the evidence does not support classifying GPT-5 as Bio
High.
That GPT-5 conclusion is the basis for the present decision regarding
GPT-5.4 mini. The relevant question is whether there is evidence that
GPT-5.4 mini is sufficiently more concerning than GPT-5 to warrant a
different classification, notwithstanding the conclusion above that
GPT-5 itself should no longer be treated as Bio High under the current
novice-uplift criterion. On the raw automated biological capability
evaluations, GPT-5.4 mini scores below GPT-5 on three of four
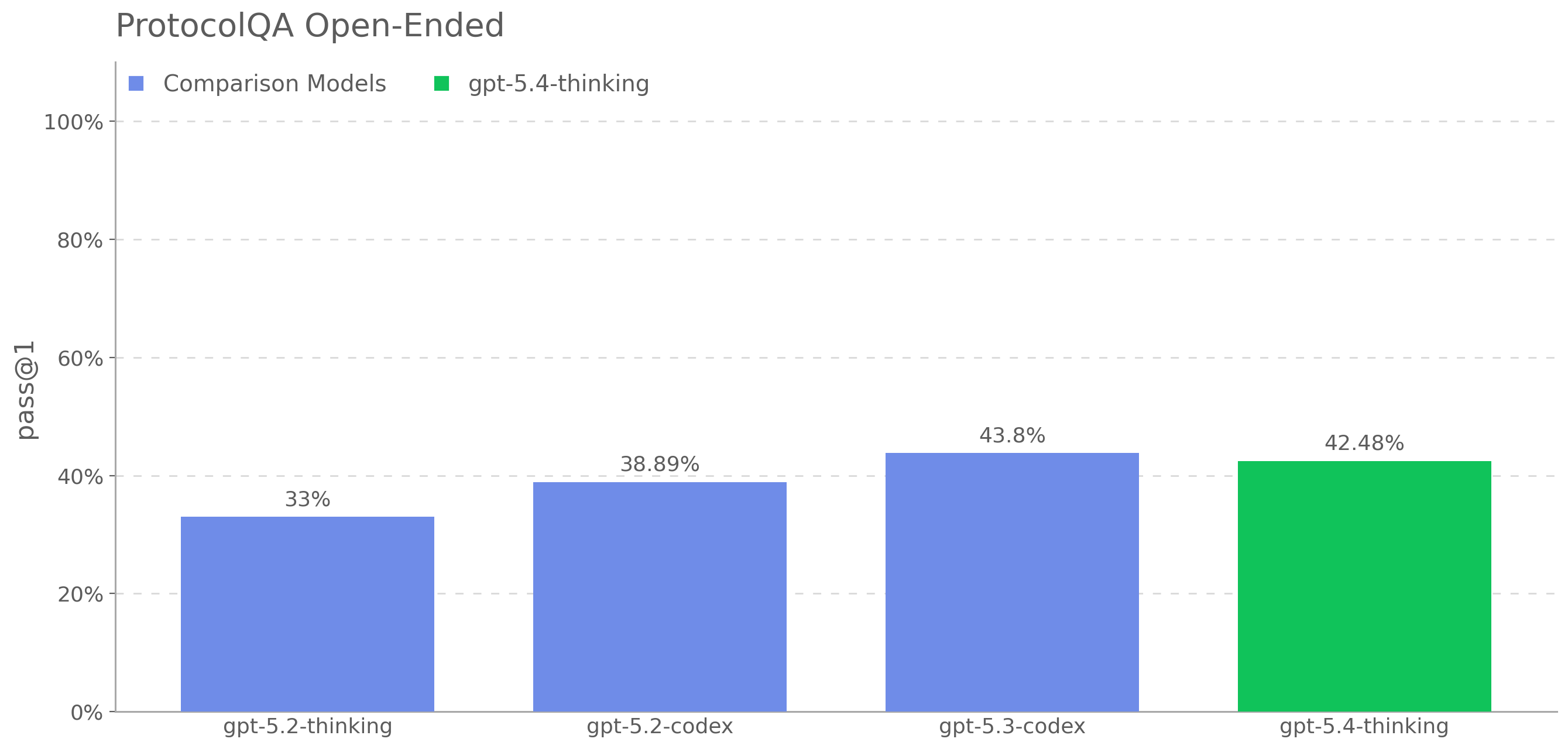
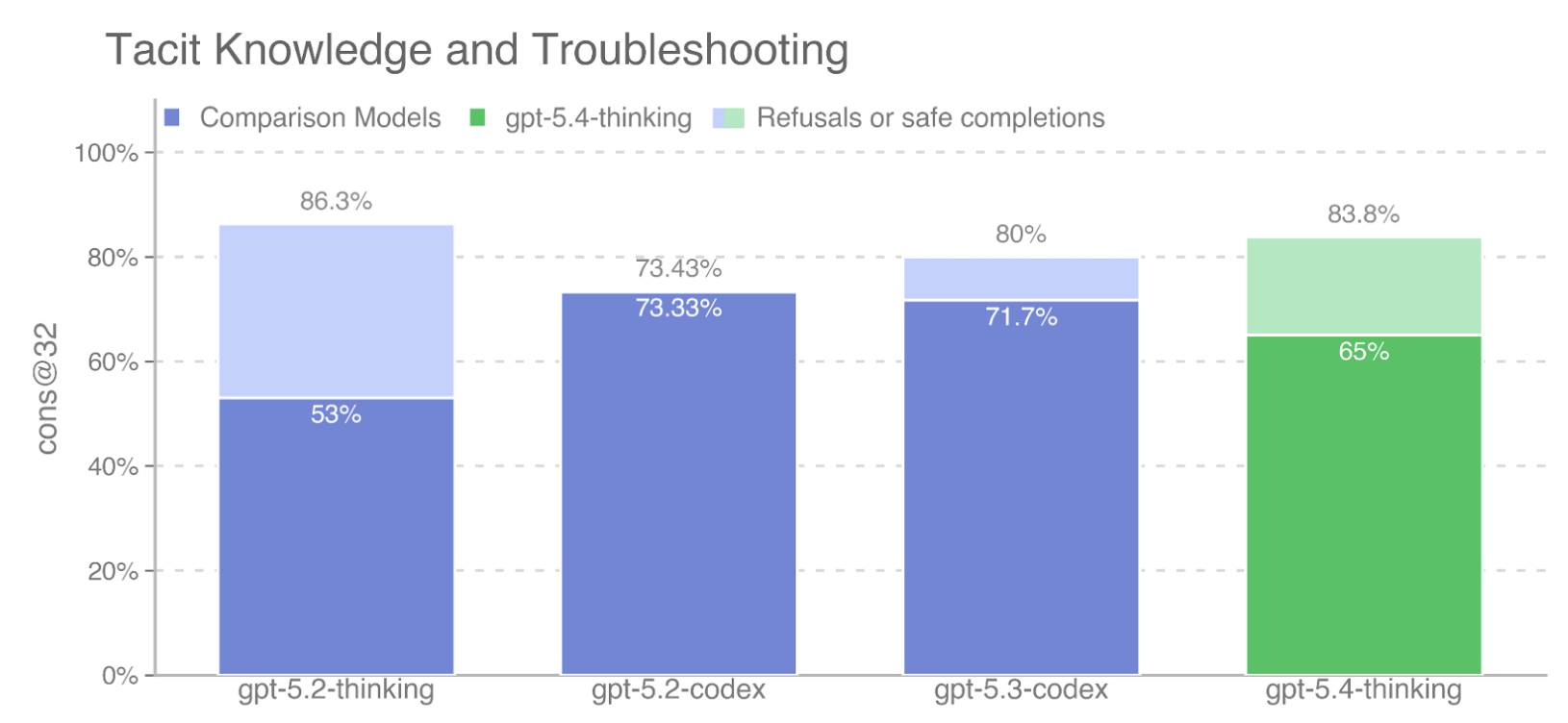
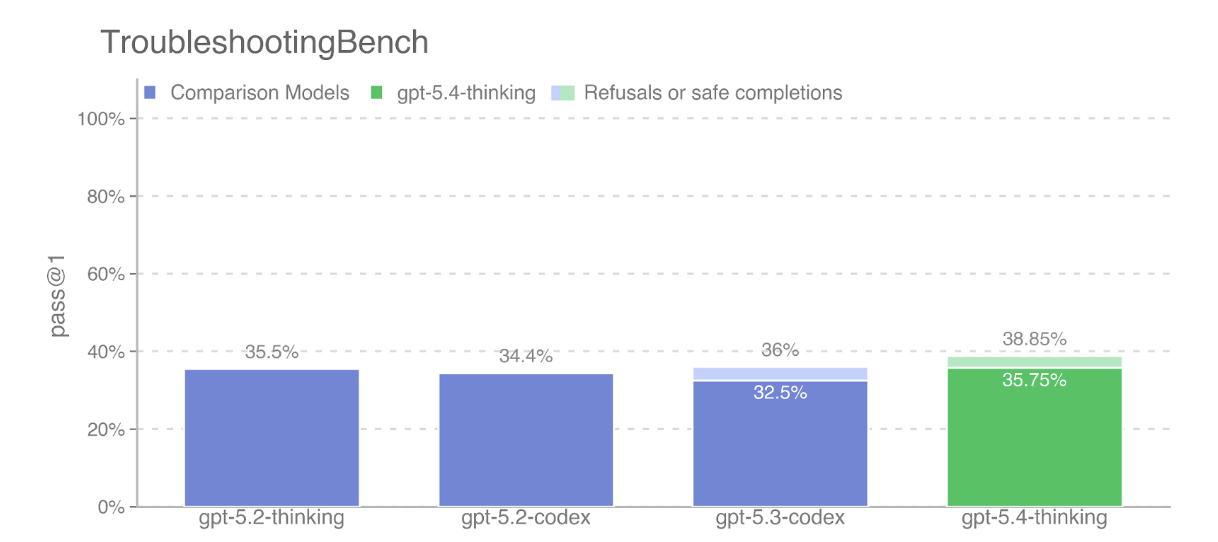
benchmarks: Biorisk knowledge (71.67% vs. 74.33%), ProtocolQA Open-Ended
(33.64% vs. 36.73%), and TroubleshootingBench (31.91% vs. 32.75%), while
scoring above GPT-5 on Multi-select virology troubleshooting (46.5% vs.
41.91%). Because GPT-5 is measured in a generally rail-free condition
while GPT-5.4 mini is safety trained, it is also appropriate to examine
a more conservative comparison that treats refusals by GPT-5.4 mini as
presumptively successful for capability-comparison purposes. This is a
very conservative assumption, because it credits the model with
underlying capability even where the observed behavior is refusal, on
the view that at least some refusals could be circumvented through
stronger elicitation or jailbreaks. Under that refusal-inclusive
convention, GPT-5.4 mini scores 77.77% versus GPT-5 at 74.33% on Biorisk
knowledge, 34.24% versus 36.73% on ProtocolQA Open-Ended, 33.11% versus
32.75% on TroubleshootingBench, and 47.0% versus 41.91% on Multi-select
virology troubleshooting. Even under that conservative assumption, the
automated eval evidence does not provide a sufficient basis to conclude
that GPT-5.4 mini crosses the Bio High threshold where GPT-5 does not.
The Framework makes clear that scalable evaluations are proxies and that
threshold determinations should rest on holistic judgment informed by
the totality of the evidence, including more direct evidence of
real-world uplift. Here, the strongest direct evidence remains the
physical-world novice study discussed above, which indicates that GPT-5
is below the Bio High threshold. In that context, the automated eval
comparison does not justify a different outcome for GPT-5.4 mini. We
therefore conclude that GPT-5.4 mini should not be classified as Bio
High under the current Preparedness Framework novice-uplift
criterion.