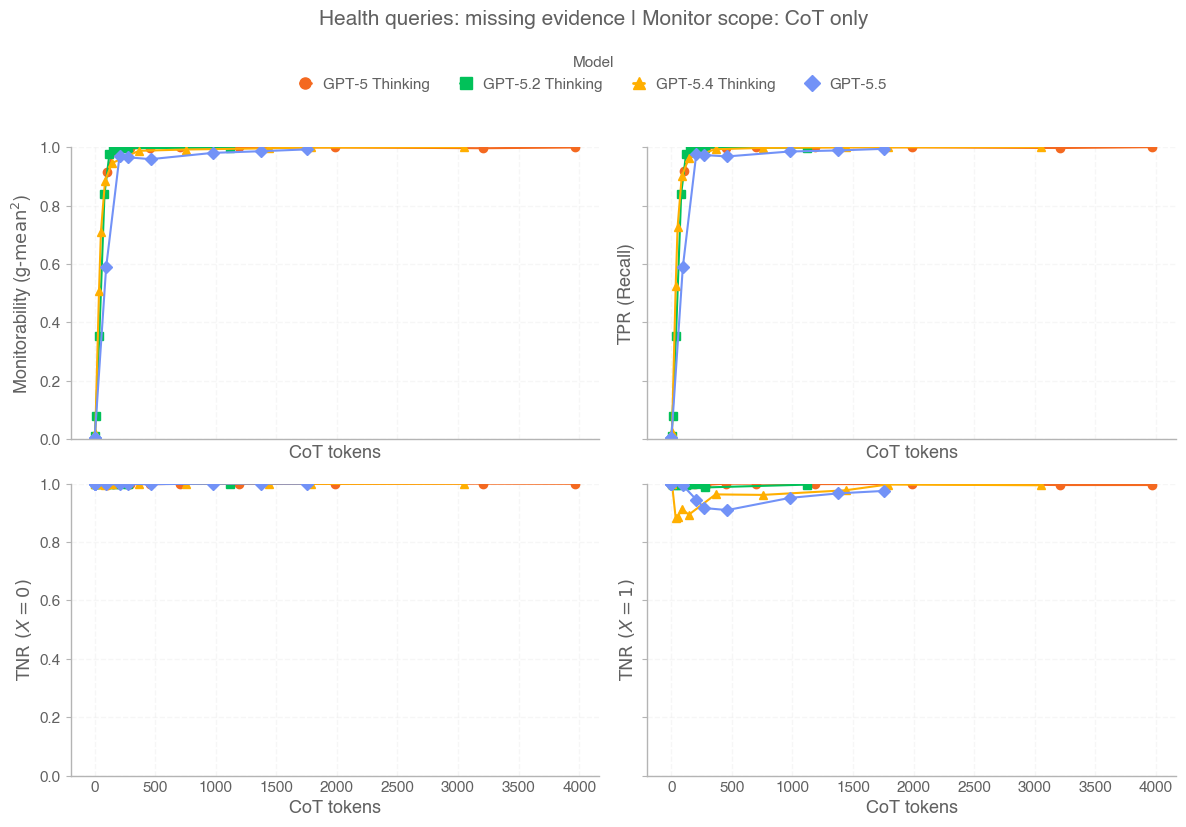
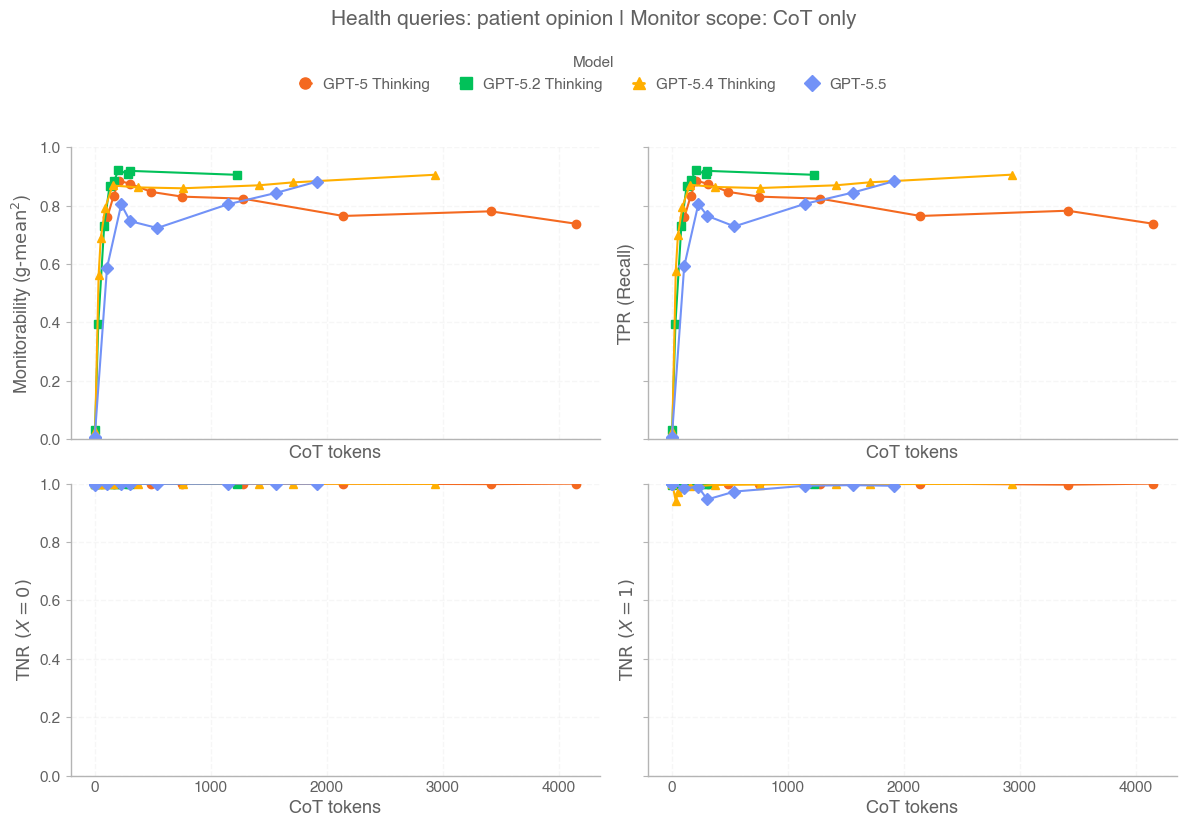
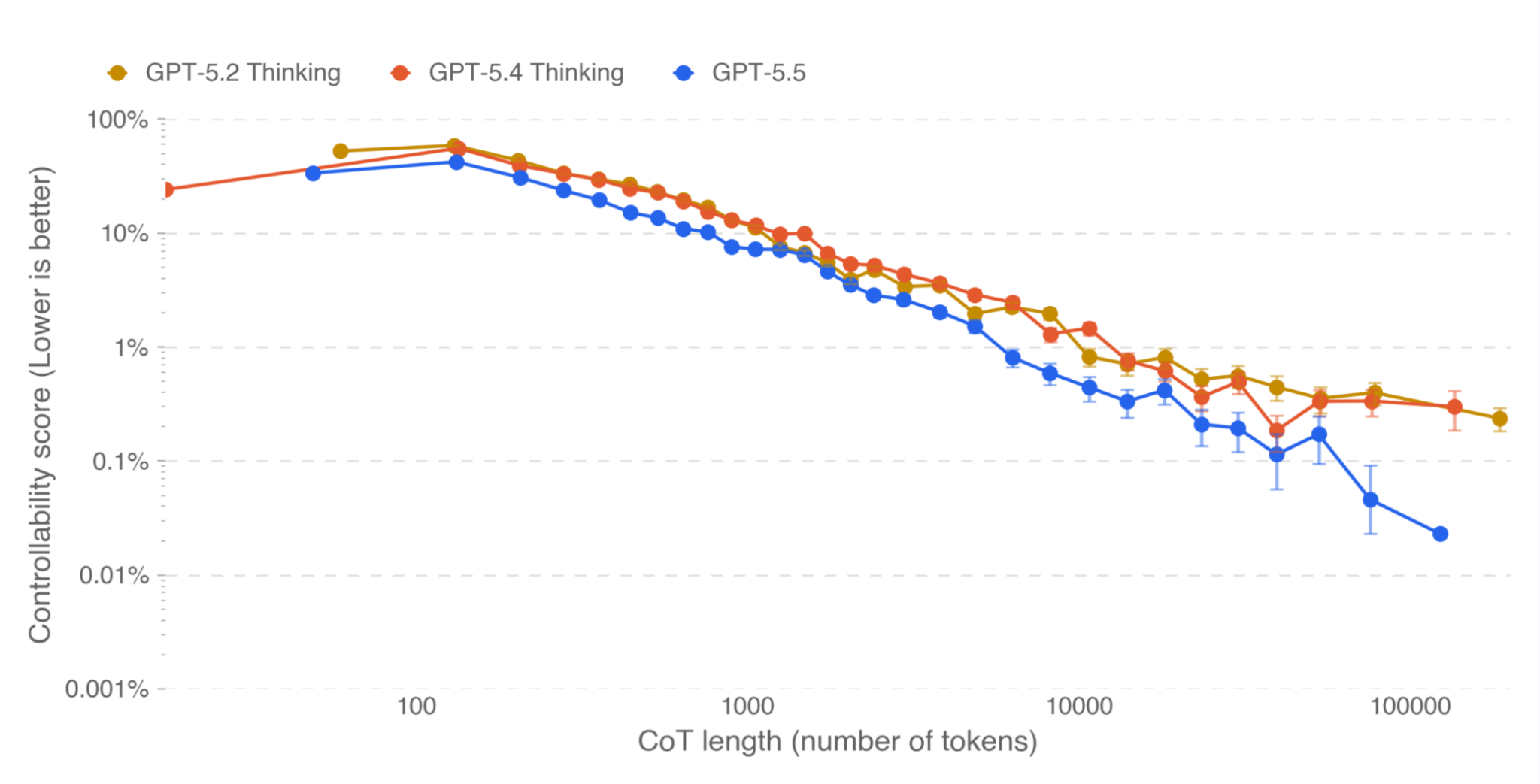
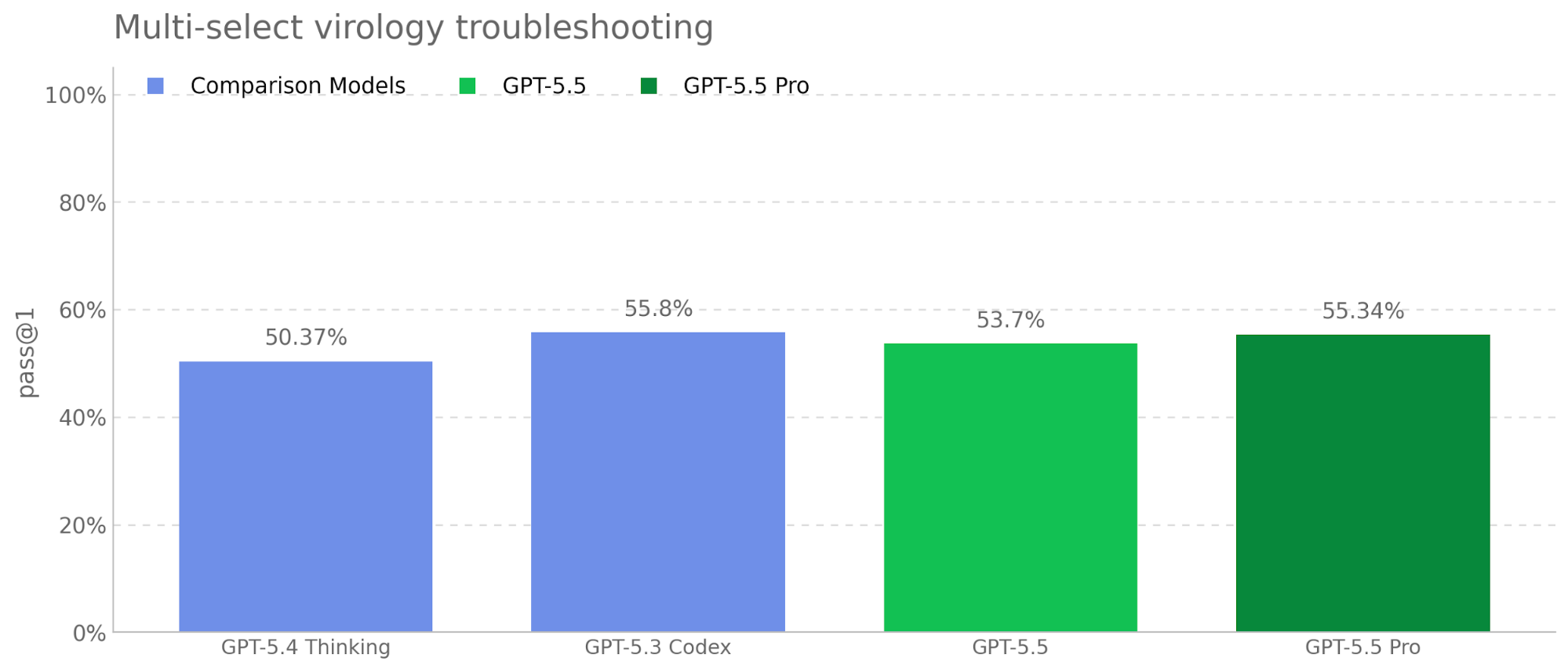
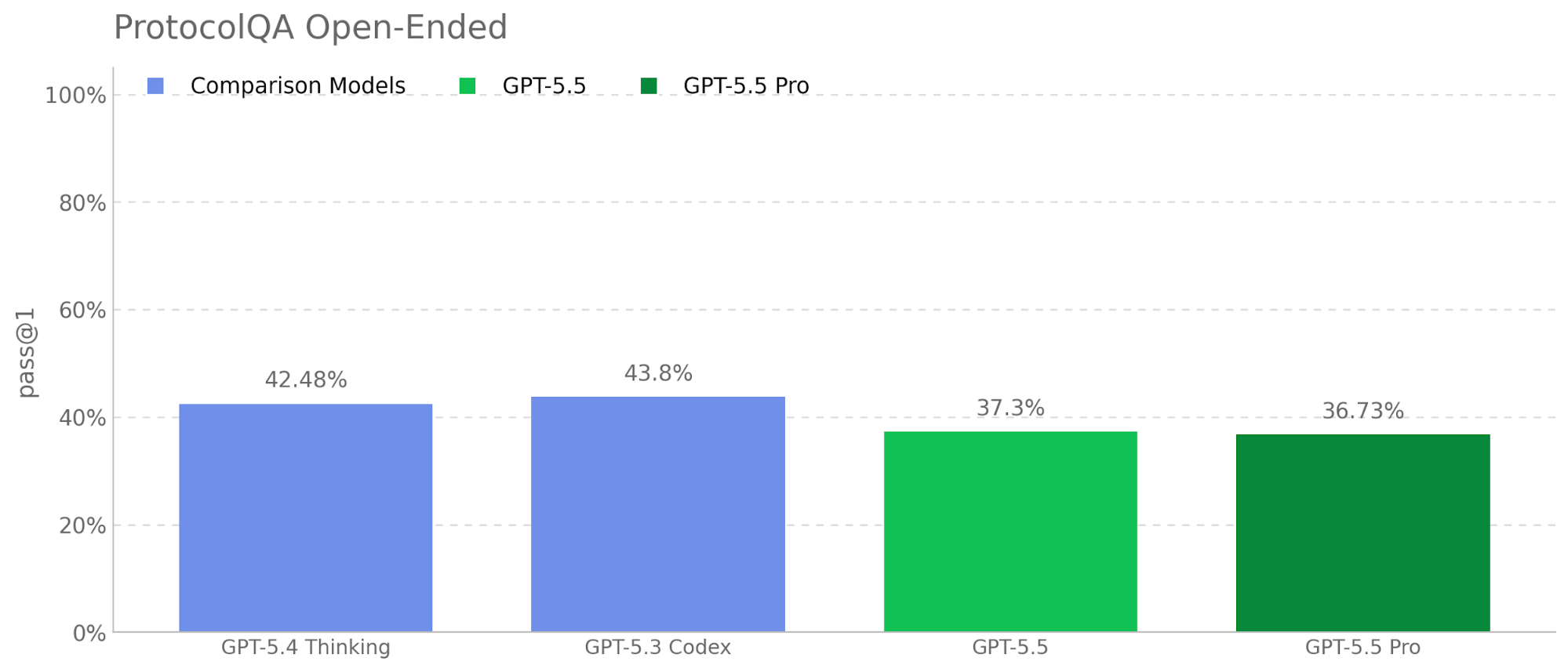
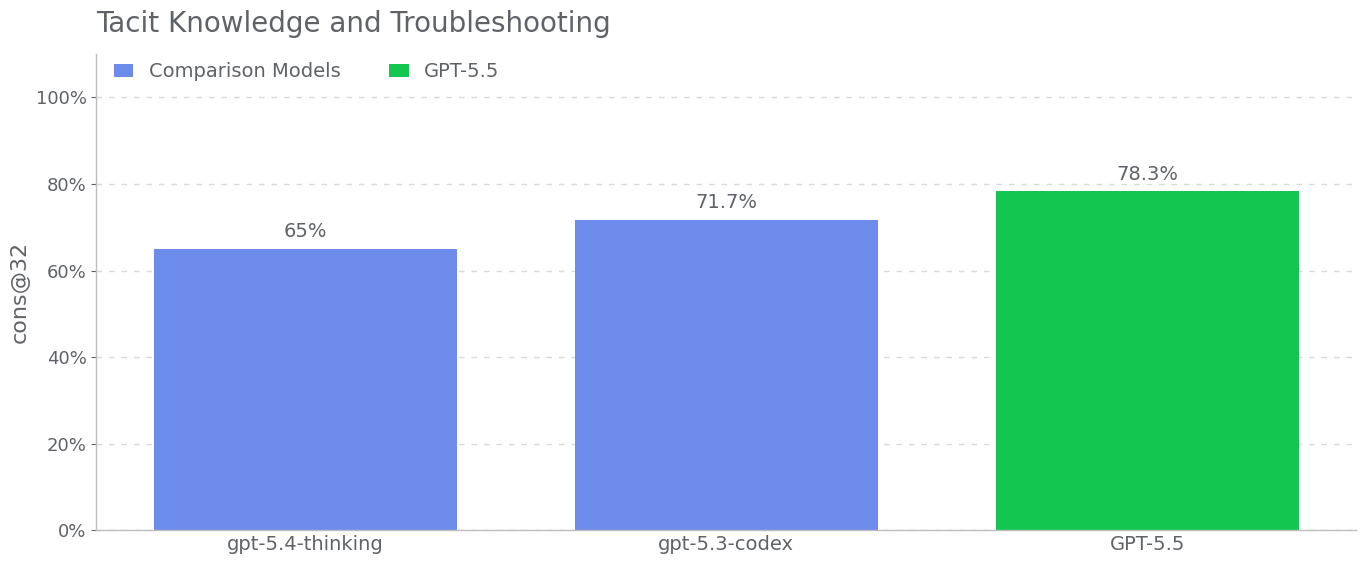
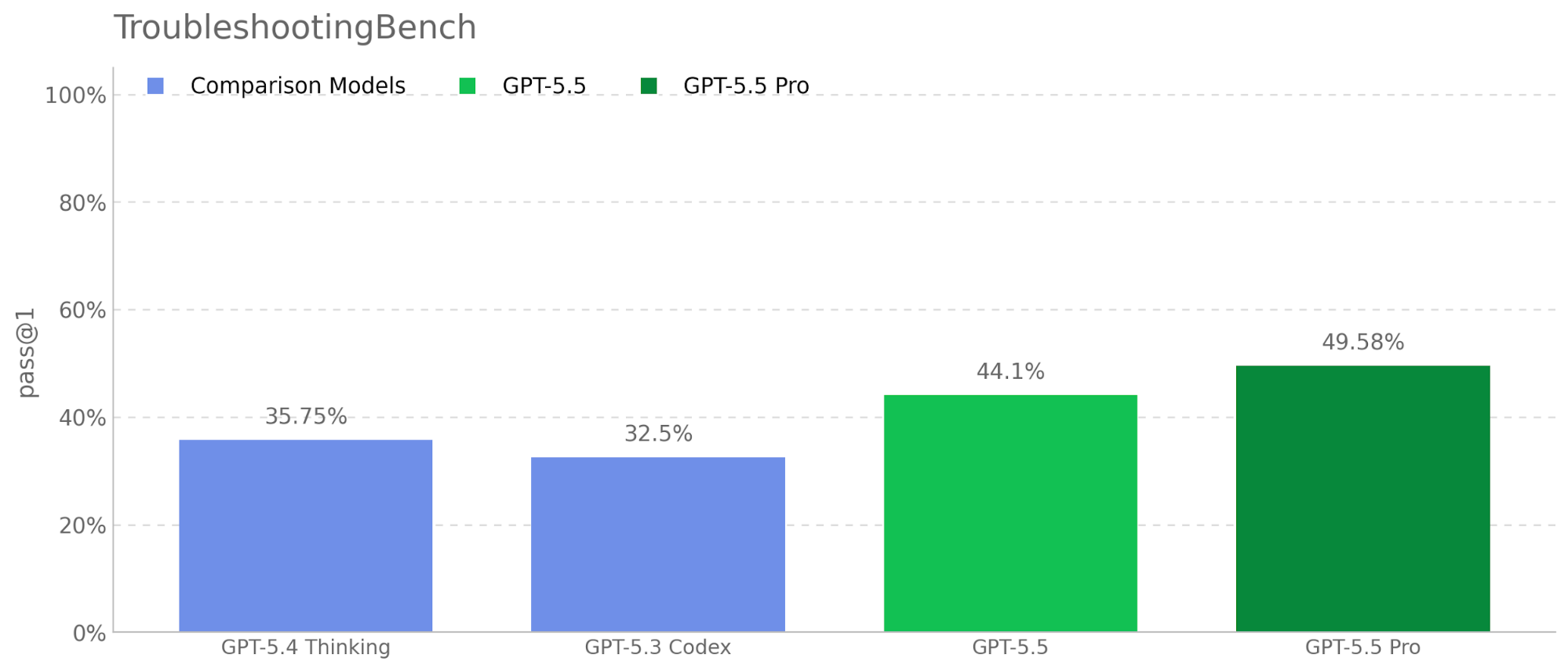
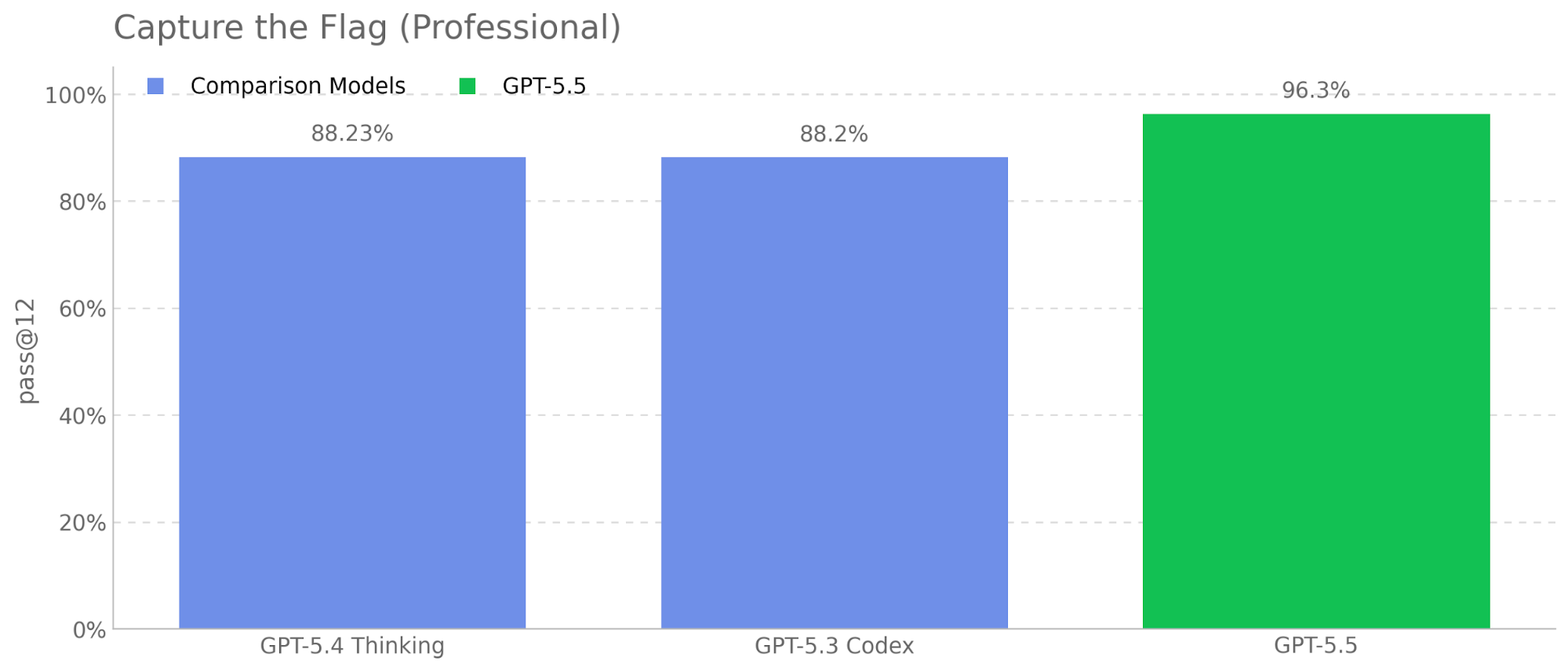
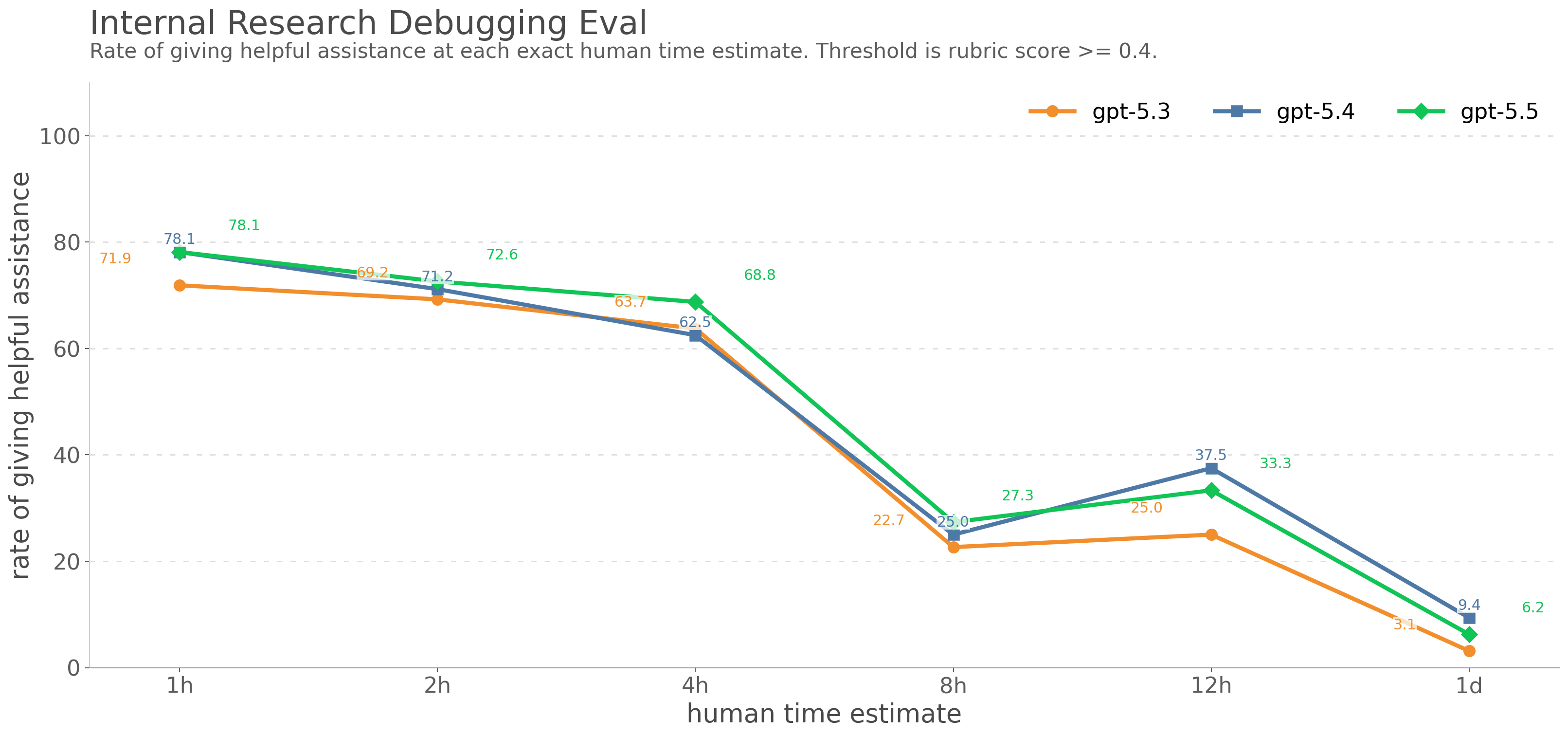
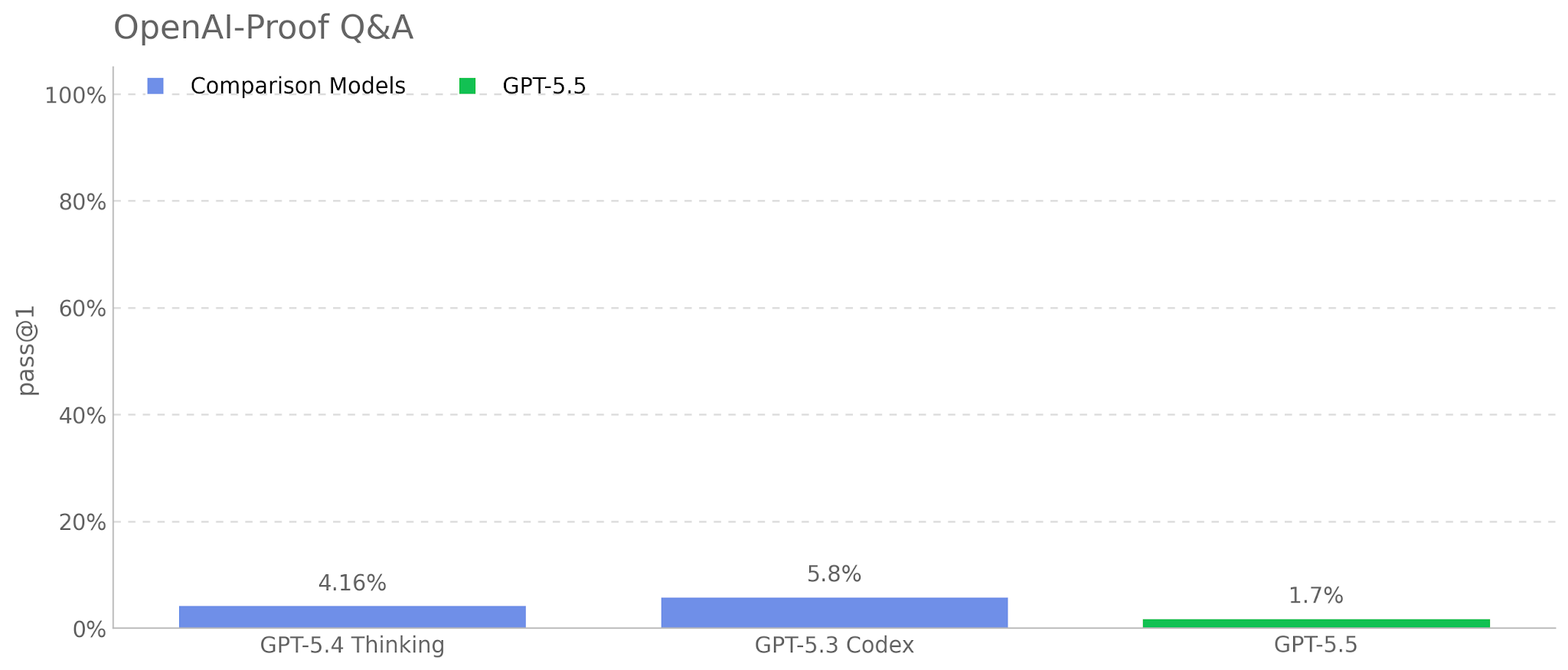
GPT-5.5 is a new model designed for complex, real-world work, including writing code, researching online, analyzing information, creating documents and spreadsheets, and moving across tools to get things done. Relative to earlier models, GPT-5.5 understands the task earlier, asks for less guidance, uses tools more effectively, checks it work and keeps going until it’s done.
We subjected the model to our full suite of predeployment safety evaluations and our Preparedness Framework, including targeted red-teaming for advanced cybersecurity and biology capabilities, and collected feedback on real use cases from nearly 200 early-access partners before release. We are releasing GPT-5.5 with our strongest set of safeguards to date, designed to reduce misuse while preserving legitimate, beneficial uses of advanced capabilities.
We generally treat GPT-5.5’s safety results as strong proxies for GPT-5.5 Pro, which is the same underlying model using a setting that makes use of parallel test time compute. As noted below, we separately evaluate GPT-5.5 Pro in certain cases because we judge that the setting could materially impact the relevant risks or appropriate safeguards posture. Except where noted, the results in system cards describe evaluations we ran in an offline setting.
This card was updated on April 24, 2026 to include additional information about safeguards for the deployment of GPT-5.5 and GPT-5.5 Pro in the API.